


RESPONSABILIDAD DEL USUARIO, FALLOS EN LOS PROMPTS Y LA CONTRA-INTELIGENCIA ARTIFICIAL.
PRÓLOGO REFLEXIVO
En un mundo donde la frontera entre lo real y lo virtual se difumina progresivamente, la inteligencia artificial se erige como una fuerza capaz de transformar sociedades enteras y redefinir la esencia misma de nuestro conocimiento. Sus algoritmos pueden componer música, redactar crónicas históricas y hasta argumentar ante un tribunal con una pericia pasmosa. Sin embargo, bajo esta aparente infalibilidad, subyace un fenómeno inquietante y apenas descifrado: la “ilusión” o “alucinación” de la IA.
Estas alucinaciones pueden surgir como simples lapsos de lógica, pero también pueden adquirir formas más sofisticadas, comprometiendo datos sensibles o fomentando desinformación masiva. En una realidad donde la innovación no solo está impulsada por el genio humano, sino también por la potencia de códigos capaces de aprender y mutar a voluntad, la línea que separa el error fortuito del engaño deliberado se torna cada vez más tenue.
Al tiempo que la computación cuántica promete revolucionar la verificación y la capacidad de procesar enormes espacios de información —abriendo la puerta a módulos híbridos que podrían discernir en tiempo real las sombras de la ficción generada por la IA—, la responsabilidad recae, en última instancia, en las manos humanas. Somos nosotros quienes diseñamos los algoritmos, interpretamos sus respuestas y, sobre todo, decidimos hasta qué punto confiamos ciegamente en un ente que genera patrones.
Este panorama futurista nos reclama una profunda reflexión ética y legal: ¿Qué ocurre cuando un modelo generativo “finge” datos convincentes y los presenta como hechos objetivos y reales? ¿Hasta dónde llega la responsabilidad del usuario que se ampara en esa respuesta y la difunde sin el debido contraste? ¿Cómo protegeremos nuestros propios sistemas contra intrusiones diseñadas por otras IAs maliciosas, en una inminente guerra de “contrainteligencias” automatizadas?
La auténtica revolución no consiste únicamente en presenciar el avance de las máquinas, sino en la manera en que respondemos a su potencial creativo y destructivo. Las ecuaciones y códigos que impulsan estas tecnologías pueden fungir como puentes de progreso o como semillas de confusión global. Bajo la nueva era cuántica, la ilusión podría tornarse más sutil; pero, bien aprovechada, esta misma tecnología podría convertirse en la mayor guardiana de la verdad y la consistencia. Así, nos encontramos ante una encrucijada histórica, donde la convergencia entre la IA y la computación cuántica nos invita a imaginar —con asombro y cautela— el advenimiento de sistemas capaces no solo de generar realidades, sino de proteger las nuestras, sustentando nuevas estructuras de responsabilidad civil, penal y, por sobre todo, humana
TABLA ÍNDICE:
| N.º | TÍTULO / SECCIÓN | DESCRIPCIÓN BREVE | SUBTEMAS / PUNTOS CLAVE |
|---|---|---|---|
| 1 | Introducción | Presenta la temática de las “ilusiones” o “alucinaciones” de la IA, ejemplificado con el primer caso legal de uso negligente de ChatGPT (Mata vs. Avianca, Inc.). Explica cómo un abogado utilizó IA para redactar argumentos con citas falsas, lo que provocó sanciones y debates sobre la responsabilidad del usuario. | – Contexto del caso “Mata vs. Avianca, Inc.” – Abogado que presenta jurisprudencia inexistente – Riesgos de usar IA sin verificación – Relevancia de la supervisión en ámbitos jurídicos |
| 2 | El fenómeno de la “Ilusión de la IA” | Define qué son las alucinaciones o ilusiones en sistemas IA (respuestas coherentes pero inexactas o inventadas). Aborda causas, implicaciones y la necesidad de comprender cómo se entrenan y sesgan los modelos de lenguaje. | 2.1. ¿Qué son las alucinaciones? – Modelos generativos basados en correlaciones estadísticas – Falta de verificación o actualización Algunos modelos de lenguaje producen contenido inexacto o imaginario, lo que puede fomentar desinformación y extremismos si el usuario no entiende la limitación y la naturaleza estadística del sistema. 2.2. Origen del problema – Falta de razonado simbólico – Sesgos en los datos 2.3. Consecuencias – Difusión de información falsa – Decisiones erróneas – Confianza indebida 2.4 tabla Resumen. |
| 3 | Responsabilidad del usuario al generar prompts defectuosos | Se plantea la cuestión de la responsabilidad compartida entre desarrolladores/proveedores de IA y el usuario que genera las instrucciones (prompts). Se explica cómo un prompt malicioso o negligente puede fomentar la difusión de contenidos ilícitos o inexactos. | – Rol del usuario en la causalidad del daño – Conocimiento del daño potencial – Falta de verificación humana antes de publicar o difundir la respuesta |
| 4 | CAPÍTULO I: Responsabilidad Civil | Explica las bases jurídicas de la responsabilidad civil por prompts defectuosos o maliciosos. Se detallan diferentes modalidades (falta de diligencia, negligencia, responsabilidad objetiva) y ejemplos en varias jurisdicciones (EE. UU., Venezuela). | 4.1. Fundamentos RC: negligencia, producto defectuoso, falta de diligencia 4.2. Ejemplos EE. UU.: brechas de seguridad (Equifax, Target) 4.3. Ejemplos Venezuela: filtración de datos, ERP defectuosos, responsabilidad contractual 4.4. Daños indemnizables: daño moral, lucro cesante, etc. |
| 5 | Prevención y cláusulas contractuales. | Describe medidas preventivas en la implementación de IA (disclaimers, protocolos internos de revisión, pólizas de seguros) para limitar los riesgos civiles. | – Cláusulas de advertencia – Procedimientos internos de control – Seguros de responsabilidad civil |
| 6 | CAPÍTULO II: Responsabilidad Penal. | Se analiza cómo la responsabilidad penal se aplica cuando hay intencionalidad (dolo) o imprudencia grave en la generación de prompts que deriven en delitos como calumnia, injuria, incitación al odio o difusión de malware. | 6.1. Dolo: intención de difundir info falsa o cometer delitos 6.2. Culpa o imprudencia: descuido grave sin verificar veracidad 7. Tipificación: delitos contra el honor, delitos informáticos, discriminación 8. Límite de la cadena causal: grado de previsibilidad del usuario |
| 7 | Soluciones Teóricas para Corregir o Prevenir las “Ilusiones”. | Expone mecanismos para mitigar la generación de contenidos falsos: verificación de hechos (fact-checking), IA explicable, normas regulatorias, estrategias contractuales y formación de usuarios. | 9.1. Soluciones tecnológicas: verificación, XAI, validación cuántica 9.2. Soluciones regulatorias: AI Act UE, códigos de ética 9.3. Cultura de uso: educación digital, alertas de contenido, responsabilidad y prudencia 9.4. Cómo ser ingeniero de prompts calificado |
| 8 | Conclusiones y sugerencias. | Se enfatiza la importancia de un manejo responsable de la IA, la supervisión humana y la actualización de modelos. Se recomienda un “Patrón de Interacción Invertida” (IA pregunta primero) y personalización según perfil del usuario. INGENERIA DE PROMPTS | – Mitigar alucinaciones con suficiente contexto – Validar la información (fuentes, búsquedas adicionales) – Reforzar la interacción IA-Usuario con prompts precisos y efectivos. tablas para redactar prompts. |
| 9 | La ILUSION y la “Contrainteligencia Artificial”. | Ilusión de la I.A, introducción del Concepto de técnicas y herramientas de IA para reforzar acciones de contrainteligencia, proteger activos e identificar amenazas y usos malintencionados de la tecnología. | – Automatizar vigilancia y respuesta al prompt – Análisis de grandes volúmenes de datos – Incorporación de IA para prever intrusiones o sabotajes |
| 10 | Ecuaciones y sugerencias de códigos. | Presenta fundamentos teóricos de validación cuántica (swap test, fidelidad cuántica) y ejemplos de uso de Qiskit y BB84. Muestra el potencial de integrar la computación cuántica para verificar la veracidad de las respuestas generadas por IA. | – Swap Test: medir consistencia entre estados cuánticos – Fidelidad cuántica: estimar similitud entre 2 estados – BB84: protocolo de distribución cuántica de claves – Aplicación a la detección de “ilusiones” en IA |
| 11 | Integración de módulos cuánticos para verificación de IA. | Se propone combinar IA y computación cuántica en un módulo Q‑CounterIllusion, para comparar la salida de un modelo generativo con un corpus verificado, reforzando la trazabilidad y reduciendo riesgos de alucinación. | – Verificación cuántica para combatir errores inherentes de la IA – Retroalimentación continua para reducir salidas engañosas – Blockchain y smart contracts para auditar veracidad |
| 12 | Perspectivas futuras y estrategia de Contrainteligencia Artificial. | A mediano y largo plazo, el uso de “módulos de contra-IA” busca mitigar alucinaciones incluso ante prompts maliciosos. Proponen la sinergia entre seguridad cuántica, sistemas de IA y normas regulatorias para asegurar un uso confiable. | – IA confiable libre de “ilusiones” – Filtro de consistencia en tiempo real – Impulso de la responsabilidad compartida (usuario, desarrollador, proveedor) |
| 13 | Ventajas de la computación cuántica para combatir ilusiones. | Expone en tabla cómo la computación cuántica añade potencia de verificación y solidez en la detección de inconsistencias, facilitando la validación de datos en entornos sensibles. | – Propiedades únicas: superposición, entrelazamiento – Evaluación más robusta contra errores y sesgos – Especial relevancia en aplicaciones críticas (salud, legal, finanzas) |
| 14 | Resumen Ejecutivo. | Conclusiones globales acerca de la necesidad de supervisión humana, la mejora tecnológica (modelos cuánticos, XAI) y la responsabilidad ética y legal compartida. | – Cultura de uso responsable y educación – Avances regulatorios y contractuales – Fomento de la transparencia en la adopción de IA |
| 15 | Bibliografía. | Lista de referencias principales, incluyendo artículos científicos, legislación, sentencias judiciales, estándares ISO y libros sobre IA, derecho, computación cuántica y ciberseguridad. | – Autores, enlaces y notas breves de cada fuente – Normativa internacional (AI Act, OECD, ISO) – Casos legales relevantes (Mata v. Avianca, Equifax, Target) |
1. Introducción.
La rápida adopción de sistemas de Inteligencia Artificial (IA), en particular aquellos basados en modelos generativos, (como GPT, BERT o redes neuronales profundas), ha impulsado un debate intenso sobre las denominadas “ILUSIONES DE LA IA” o “ALUCINACIONES”. Estos términos se refieren a la capacidad de los modelos de generar respuestas con alto nivel de coherencia lingüística, pero que pueden ser inexactas, inventadas o contradictorias con respecto a la realidad factual o al conocimiento verificado, muchas veces ocasionadas porque el modelo de IA, es alimentado por datos defectuosos o las instrucciones impartidas no corresponden a una correcta ingeniería de prompts.
El comienzo del primer caso legal de alucinación, aconteció en el mes de mayo de 2023, y se hizo público en una disputa judicial en la Corte del Distrito Sur de Nueva York (Estados Unidos) donde un abogado presentó un escrito legal con citas de jurisprudencias inexistentes generada por ChatGPT. A grandes rasgos sucedió lo siguiente:
- El caso:
- El asunto principal era “Mata Vs. Avianca, Inc.”, un litigio relacionado con lesiones personales durante un vuelo.
- El abogado, Steven A. Schwartz (del bufete Levidow, Levidow & Oberman, con sede en Manhattan), preparó un memorando legal para el juez.
- Uso de ChatGPT:
- El abogado empleó la herramienta de IA, ChatGPT para encontrar y redactar argumentos jurídicos en su escrito.
- ChatGPT “alucinó” (inventó) casos y precedentes, es decir, proporcionó citas de asuntos judiciales que no existían en ninguna Corte.
- Problema con las citas:
- Entre los ejemplos de casos falsos se encontraban citados “Martínez v. Delta Air Lines” y “Zicherman v. Korean Air Lines Co.”, que nunca se habían dictaminado o publicado no formando parte de la jurisprudencia de esa jurisdicción.
- El juez descubrió que las citas no eran verificables; los supuestos precedentes judiciales no figuraban en ningún archivo legal oficial.
- Consecuencias:
- El tribunal exigió aclaraciones y confirmó que efectivamente las referencias habían sido fabricadas por la herramienta de IA.
- El abogado enfrentó potenciales sanciones por presentar documentación falsa. Posteriormente, tanto él como el bufete admitieron su error y pidieron disculpas al juez.
Este incidente se convirtió en un precedente judicial relevante de los riesgos de utilizar modelos de lenguaje como ChatGPT u otros sin supervisión ni verificación adicionales en ámbitos profesionales sensibles, como el legal.
En este escenario, conviene analizar no solo los fallos intrínsecos de la tecnología derivada de la inteligencia artificial, sino también la responsabilidad de los usuarios que emiten instrucciones o prompts de forma negligente o deliberada, así como la forma en que estos comportamientos podrían derivar en consecuencias civiles y penales.
En el presente artículo de opinión se abordan:
- El fenómeno de la ilusión de la IA y sus causas.
- La responsabilidad del usuario al generar prompts defectuosos, dividida en dos capítulos principales:
- Capítulo I: Responsabilidad Civil
- Capítulo II: Responsabilidad Penal
- Propuestas, soluciones teóricas y tecnológicas a la que denominaremos el uso de LA CONTRA INTELIGENCIA ARTIFICIAL, para mitigar las alucinaciones de la IA, tanto desde la perspectiva tecnológica como regulatoria y de buenas prácticas.
2. El fenómeno de la “Ilusión de la IA”.
2.1. ¿Qué son las alucinaciones o ilusiones de la IA?.
Los grandes modelos de lenguaje y otras IA generativas se entrenan sobre enormes conjuntos masivos de datos. Su mecanismo principal se basa en correlaciones estadísticas: predicen la palabra o secuencia lógica siguiente más probable en función de patrones aprendidos. Esta aproximación, si bien resulta extremadamente poderosa, no garantiza la verificación ni la coherencia lógica profunda, además el modelo puede estar desfasado y apoyado contextos científicos no actualizados, lo que profundiza la posibilidad de manejar criterios en desuso.
2.2. Origen del problema.
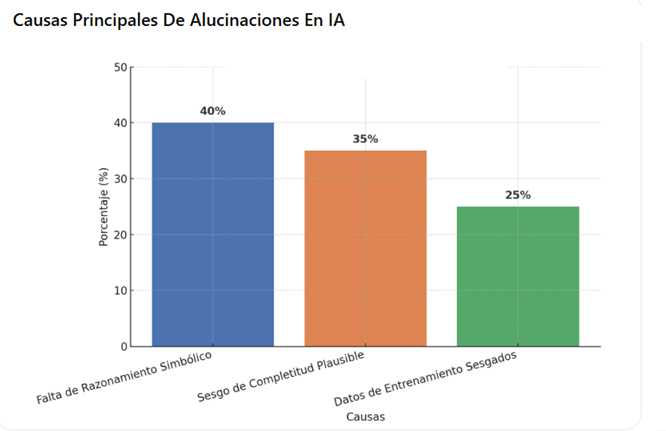
- Falta de razonado simbólico: Muchos sistemas carecen de una “capa” que compruebe o infiera datos con reglas lógicas o información verificada.
- Tendencia al completado plausible: Si el modelo “no sabe” algo, y en su afán de dar una solución expedita al prompt del usuario la IA tiende a “inventar la respuesta” usando correlaciones, generando datos erróneos incluso inventados con apariencia de verdad.
- Sesgos en el entrenamiento: Los datos de entrenamiento pueden contener errores, sesgos culturales, desinformación o distribuciones poco representativas.
- Los LLM no “razonan”: predicen palabras probables en secuencia, y en ocasiones generan información falsa (pero verosímil). Esta “alucinación” en strictu sensu no es mentir, sino una consecuencia de su mecanismo de “patrones estadísticos”. Para usos críticos (sector legal, educativos, financiero), debe existir siempre una verificación y supervisión humana.
2.3. Consecuencias:
- Difusión de información falsa o difamatoria: Por ejemplo, atribuir a una persona acciones o hechos que nunca realizó.
- Decisiones perjudiciales: En sectores críticos (salud, finanzas, jurídico) una alucinación de la IA puede causar daños económicos, reputacionales o incluso poner en riesgo la seguridad de individuos. En la historia comentada del empleo de citas jurisprudenciales irreales, la consecuencia no solo fue una medida disciplinaria a los abogados, sino el fracaso del caso judicial, lo que sin lugar a dudas genera costas procesales a la parte perdidosa.
- Confianza indebida: Usuarios que dan por ciertas las respuestas de la IA sin haber realizado ningún contraste o verificación posterior.
2.4 “Tabla de Síntesis sobre las Alucinaciones de IA”
| Tema | Descripción |
|---|
| Definición de Alucinaciones de IA | Se refiere a situaciones en las que un modelo de IA (como un LLM) genera información que parece exacta pero que, en realidad, es inexacta, irrelevante o carece de sentido. Es análogo a cómo los humanos pueden experimentar alucinaciones. |
| Ejemplo Relevante | El caso de ChatGPT que afirmó falsamente que un alcalde australiano había sido declarado culpable de soborno y encarcelado, cuando en realidad el alcalde había reportado un caso de soborno a las autoridades. |
| Factores que Contribuyen | – Sesgos en los datos de entrenamiento – Entrenamiento limitado – Complejidad del modelo – Falta de supervisión humana – Interpretación de patrones no basados realmente en el contexto |
| Problemas Causados por Alucinaciones de IA | – Información inexacta que puede generar confusión – Creación de contenidos sesgados o engañosos – Errores en ámbitos sensibles, como documentación legal, medicina o vehículos autónomos, que podrían derivar en consecuencias graves |
| Métodos de Mitigación | – Eliminar sesgos en el conjunto de datos de entrenamiento – Entrenar modelos extensamente con datos de alta calidad – Evitar la manipulación intencional de los datos de entrada – Evaluación y mejora continua de los modelos – Ajuste fino (fine-tuning) del modelo en datos específicos de un dominio |
| Buenas Prácticas para la Prevención | – Vigilar y revisar sistemáticamente la información generada (supervisión humana regular) – Comprender las limitaciones: los modelos no entienden el significado de las palabras, sino que predicen patrones estadísticos – Proveer más contexto en el prompt para lograr respuestas más precisas y relevantes no dejar la búsqueda al Azar por parte del Modelo de I.A |
| Síntesis | – Las alucinaciones de IA implican la generación de respuestas que parecen acertadas pero no lo son. – Provocan riesgos importantes, como desinformación y sesgos y pueden generar responsabilidades a quienes difuminen esta data defectuosa. – Prevenir o mitigar se basa en: entrenamiento de calidad, verificación humana constante, ajuste fino, y ofrecer un contexto más amplio a los modelos para guiar la generación de contenido con mayor precisión. |
3. La responsabilidad del usuario al generar prompts defectuosos o maliciosos.
A menudo nos preguntamos : ¿Quien es el responsable?, serán los desarrolladores y/o proveedores de modelos de IA que están inmersos en la cadena desde su generación a la prestación del servicio. ¿Pero donde queda el rol del usuario?, que sin lugar a dudas es un individuo con un papel protagónico en este proceso al generar la instrucción o prompt y al no verificar ulteriormente las salidas o conclusiones proferidas por la I.A. Un prompt defectuoso o malicioso puede propiciar la generación de contenidos ilegales, difamatorios o discriminatorios.
3.1. ¿Por qué el usuario también es responsable?.
- Contribución causal al daño: Un prompt inadecuado, impreciso o sesgado es un factor determinante y condicionante de la respuesta errónea generada.
- Conocimiento de la posibilidad de daño: Usuarios expertos o con intenciones maliciosas podrían forzar el modelo a emitir contenidos dañinos o falsos.
- Control y supervisión: El usuario es la última capa de verificación antes de difundir o publicar la respuesta o salida de la IA.
A continuación, se exponen en síntesis el asunto en dos capítulos —responsabilidad civil y penal— donde puede ubicarse esta conducta.
4.–CAPÍTULO I: RESPONSABILIDAD CIVIL.
4.1 Fundamentos de la Responsabilidad Civil por prompts defectuosos
En el ámbito civil, la responsabilidad suele derivarse de la obligación de no causar un daño injusto a terceros (principio de neminem laedere). Cuando un usuario solicita respuestas a la IA que podrían causar perjuicio a otra persona u organización, es posible invocar diversos regímenes de responsabilidad.
- 4.1.1 Falta de diligencia o negligencia.
- Un usuario que, por imprudencia, introduce un prompt ambiguo o defectuoso y luego difunde la respuesta sin contrastarla, podría incurrir en responsabilidad por negligencia.
- Ejemplo: Pedirle a la IA “Resúmeme los antecedentes penales de ‘X persona’” sin verificar si esos antecedentes son reales, y luego publicar información falsa que daña la reputación de esa persona.
- 4.1.2 Responsabilidad objetiva o por producto defectuoso.
- Aunque habitualmente se discute el rol de los proveedores bajo esquemas de producto defectuoso, también se estudia la contribución del usuario que configura o “afina” el modelo. Quien integra, personaliza o “entrena adicionalmente” la IA, podría convertirse, en ciertos marcos jurídicos, en un “productor” de la nueva versión del sistema o en co-responsable.
- Esto se extiende si el usuario “remarca” o publicita el modelo con su propia marca o se presenta como su “desarrollador”.
- 4.1.3 Derecho comparado: Existen algunos precedentes de responsabilidad culposa en el manejo de la tecnología:
4.2 Estados Unidos.
- Casos de brechas de seguridad y fuga de datos (data breaches)
- Ejemplo: Caso Equifax (2017)
Equifax, una de las agencias de crédito más grandes en EE. UU., sufrió una brecha de datos que afectó a millones de personas. Se alegó que la empresa no había tomado las medidas de seguridad razonables para proteger la información confidencial. Esto dio lugar a demandas colectivas (class actions) por parte de los consumidores afectados, señalando la negligencia de la compañía al no actualizar y parchar sus sistemas a tiempo. Véase los siguientes enlaces: https://www.ftc.gov/news-events/press-releases/2019/07/equifax-pay-575-million-settlement-ftc-cfpb-states-over-data y https://corporate.target.com/press/releases/2013/12/target-confirms-unauthorized-access-to-payment-card - Ejemplo: Caso Target (2013)
Target sufrió un hackeo que expuso información financiera y personal de millones de clientes. La demanda alegaba negligencia en las medidas de ciberseguridad. Aunque hubo arreglos extrajudiciales, se considera uno de los mayores ejemplos de responsabilidad civil derivada de una brecha de seguridad atribuible a falta de controles adecuados. Véase los siguientes enlaces: http://Comunicado oficial de la FTC sobre la brecha de Equifax y https://www.equifaxbreachsettlement.com/
- Ejemplo: Caso Equifax (2017)
- Negligencia en la supervisión o en la provisión de servicios de tecnología.
- Ejemplo: Demandas contra proveedores de servicios en la nube
En casos donde un proveedor de almacenamiento en la nube pierde datos críticos de empresas clientes por no cumplir las prácticas de seguridad “estándar de la industria”. Si los clientes demuestran que hubo una omisión o falla de la diligencia debida en la protección de datos, podrían demandar por negligencia. - La mayoría de los casos de grandes brechas de seguridad culminan en acuerdos extrajudiciales (settlements) con múltiples partes: consumidores, estados y agencias federales. Sitios como PACER (en EE. UU.) resultan muy útiles para encontrar los documentos judiciales reales (presentaciones de la demanda, mociones, órdenes del tribunal, etc.).Para casos grandes como Equifax y Target, se crearon sitios web específicos que centralizan la información del acuerdo y explican cómo podían reclamar los afectados. Dichos sitios pueden haber sido archivados luego de cerrarse el plazo de reclamación. Fuentes de noticias confiables (The New York Times, Reuters, CNN, etc.) proporcionan perspectivas y cronologías detalladas de los eventos y las consecuencias legales.
- Ejemplo: Demandas contra proveedores de servicios en la nube
- Se han mencionado algunos enlaces (URL) y referencias para profundizar en la información sobre los casos de Equifax (2017) y Target (2013). Estos enlaces apuntan a documentos oficiales, noticias de medios digitales y/o sitios web de instituciones que participaron directamente en el manejo legal de las brechas de seguridad.
- La mayoría de los casos de grandes brechas de seguridad culminan en acuerdos extrajudiciales (settlements) con múltiples partes: consumidores, estados y agencias federales. Sitios como PACER (en EE. UU.) resultan muy útiles para encontrar los documentos judiciales reales (presentaciones de la demanda, mociones, órdenes del tribunal, etc.). Para asuntos judiciales de mayor cuantía como Equifax y Target, se crearon sitios web específicos que centralizan la información del acuerdo transaccional y explican cómo podían reclamar los afectados. Dichos sitios pueden haber sido archivados luego de cerrarse el plazo de reclamación. Para mayor profundidad se puede acceder a la verificación de fuentes de noticias confiables como: The New York Times, Reuters, CNN, etc., las cuales proporcionan perspectivas y cronologías detalladas de los eventos y demás consecuencias legales circundantes a estos casos.
4.3. Venezuela.
En Venezuela, la jurisprudencia sobre responsabilidad civil por el uso negligente de la tecnología no está tan desarrollada o publicitada como en otras jurisdicciones, sin embargo, sí existen normas generales que regulan la responsabilidad civil (Código Civil venezolano Art.1.185) que exigen la concurrencia de daño, relación de causalidad y falta imputable (culpa o negligencia) para exigir indemnizaciones, también se cuenta con leyes específicas que tocan aspectos tecnológicos, como la Ley de Infogobierno, la Ley Orgánica de Ciencia, Tecnología e Innovación (LOCTI), la Ley sobre Mensajes de Datos y Firmas Electrónicas, entre otras. A continuación, algunos ejemplos hipotéticos e indicios de casos:
- Casos de filtración de datos personales y negligencia en el resguardo de bases de datos.
- Ejemplo hipotético: Una empresa proveedora de servicios de telecomunicaciones o internet que maneja datos personales de sus usuarios y sufre un ataque informático debido a medidas insuficientes de seguridad. Si se demuestra que la compañía no observó los protocolos mínimos de protección de datos (por ejemplo, no cifrar contraseñas o no actualizar sistemas operativos), los usuarios podrían exigir una reparación civil por daños y perjuicios.
- Fallas en plataformas gubernamentales o públicas que causen perjuicios a los ciudadanos.
- Ejemplo hipotético: Un sistema de registro electrónico estatal, que colapsa o expone datos personales de forma indebida, fruto de una mala implementación o supervisión. Esto podría dar cabida a reclamos de indemnización si se demuestra que el Estado o la institución responsable actuó con negligencia (omisión de estándares mínimos de ciberseguridad o falta de mantenimiento adecuado).
- Negligencia en la prestación de servicios de software a empresas.
- Ejemplo: Caso hipotético de un proveedor que implementa un ERP (sistema de planificación de recursos) con graves deficiencias. Si la solución implantada provoca pérdidas económicas considerables a la empresa cliente por errores de programación o falta de medidas de seguridad, y se evidencia que el proveedor no actuó con la diligencia esperada de un profesional del ramo (por ejemplo, no realizó pruebas de garantía, no corrigió vulnerabilidades conocidas, etc.), la empresa afectada podría demandar por daños y perjuicios.
- Caso hipotético de difamación o daño a la reputación por uso negligente de plataformas tecnológicas.
- Si una plataforma de comercio electrónico nacional no vigila adecuadamente el contenido publicado por usuarios (por ejemplo, críticas o acusaciones falsas) y esto conlleva un daño reputacional grave a terceros, se podría argumentar una responsabilidad civil por negligencia en la moderación o control razonable de la plataforma. El tema se vincula con la responsabilidad de intermediarios, que en Venezuela no está tan claramente regulada como en otras jurisdicciones, pero existe la posibilidad de reclamación civil si se demuestra que hubo una omisión grave.
En todos los casos, la clave para establecer la responsabilidad civil por negligencia tecnológica es demostrar que existía una obligación de cuidado (diligencia), que esa obligación fue incumplida y que el incumplimiento causó daño directo y cuantificable. Asimismo, cualquier demanda concreta depende de las particularidades de los hechos, de la jurisdicción y de la legislación aplicable.
Relación con el uso de tecnología.
El uso de tecnología puede generar responsabilidad civil, si:
Se causa un daño a terceros con intención, negligencia por girar instrucciones defectuosas a la IA, o imprudencia en el uso de la tecnología, también si hay un exceso en el uso de derechos relacionados con la tecnología (por ejemplo, derechos sobre datos personales o propiedad intelectual) o si se actúa con mala fe o se viola la finalidad social del uso tecnológico.
En el contexto del uso de tecnología: Es fundamental actuar dentro de los límites legales y éticos. La culpa en el uso tecnológico puede generar responsabilidad civil si causa daño a terceros o si se actúa con mala fe.
Se trae a colocación fallo de la Sala Civil – 24-02-2015 – Expediente: 14-367, el cual reitera los alcances del hecho ilícito previsto en el artículo 1.185 C.C, lo cual genera responsabilidad civil por daños materiales y morales.
- 4.4. Daños indemnizables.
Pueden incluir:- Perjuicios patrimoniales (pérdida económica)
- Daño moral o reputacional
- Daño emergente y lucro cesante (si una empresa pierde un contrato a raíz de información falsa generada por la IA tras un prompt).
5. Prevención y cláusulas contractuales.
- 5.1. Cláusulas de advertencia (disclaimers): Muchos proveedores de inteligencia artificial, exigen en sus contratos de afiliación a los usuarios incluir leyendas del tipo: “Este contenido ha sido generado con IA, se recomienda verificación adicional”. El incumplimiento podría agravar la responsabilidad del usuario.
- 5.2. Procedimientos internos de control: Organizaciones que usan IA a gran escala suelen establecer protocolos de revisión, donde cada prompt y respuesta se someten a validaciones internas antes de su publicación incluso la IA puede abstenerse de procesar la instrucción.
- 5.3. Seguro de responsabilidad civil: Algunas empresas optan por pólizas específicas que cubren reclamaciones derivadas del uso de IA.
CAPÍTULO II: RESPONSABILIDAD PENAL.
6. Bases de la responsabilidad penal del usuario
A diferencia de la responsabilidad civil (donde puede haber responsabilidad objetiva y no siempre se precisa la prueba de intención o culpa), en lo penal se requiere un elemento subjetivo: dolo (intención) o imprudencia grave.
- 6.1. Dolo:
- El usuario introduce el prompt con la clara intención de difundir información falsa o cometer un delito (p. ej. difamación, incitación al odio, fraude).
- Ejemplo: Instruir intencionalmente a la IA para generar injurias contra un rival político o comercial y difundirlas masivamente mediante una estrategia de mercado.
- 6.2. Culpa o imprudencia grave.
- Sin intención directa de delinquir, pero con un descuido grave al no verificar la veracidad de lo que la IA produce.
- Ejemplo: Compartir públicamente una respuesta de la IA que acusa falsamente a alguien de un delito, sin molestarse en contrastar la información.
7. Tipificación de conductas y jurisprudencia emergente.
- 7.1. Delitos contra el honor (calumnias, injurias).
Si un usuario, vía IA, emite declaraciones difamatorias y sabe o debería saber que son falsas, puede ser acusado penalmente. - 7.2. Delitos de odio o discriminación.
Prompts que incitan a la IA a generar contenido racista o xenófobo podrían imputarse al usuario como autor o partícipe, conforme a la legislación antidiscriminación de cada país. - 7.3. Delitos informáticos.
Generar un prompt orientado a producir malware, es decir «software malicioso» que no es otro que cualquier programa o código diseñado con la intención de dañar, explotar o comprometer dispositivos, redes o datos, propagándose de diversas maneras y puede causar diferentes tipos de daños, como el robo de información, el secuestro de archivos o la interrupción del funcionamiento de un sistema, o exhortar a la IA para facilitar phishing o violaciones de seguridad, implica responsabilidad penal dentro del ámbito de los delitos informáticos, si se concreta el hecho o se demuestra la intención punible.
Un punto clave es determinar si el acto punible “emana” directamente del usuario o si el modelo (la IA) introduce un elemento imprevisible. Sin embargo, la práctica jurídica tiende a responsabilizar al ser humano que provoca o inicia el proceso, salvo casos muy excepcionales donde la IA se comporta de forma totalmente autónoma y actúa fuera del control o previsión razonable del usuario.
8. Soluciones Teóricas para Corregir o Prevenir las “Ilusiones” de la IA.
8.1. Soluciones tecnológicas.
- Implementación de capas de verificación (fact-checking)
- Integrar módulos que contrasten las respuestas con bases de datos confiables y marcos de conocimientos sólidos.
- Modelos cuánticos de validación
- Existen propuestas de software cuántico que permiten medir la “consistencia cuántica” entre la respuesta de la IA y un conjunto de información verificada.
- El swap test, por ejemplo, evalúa la fidelidad entre dos “estados” (uno que representa la respuesta y otro que representa la verdad).
- Sistemas de XAI (Explainable AI)
- Obligar al modelo a presentar trazas o evidencias que respalden sus conclusiones, para identificar posibles “inventos” o contradicciones.
8.2. Soluciones regulatorias y contractuales.
- Normativas de IA (AI Act en la UE, propuestas en EE. UU.)
- Podrían imponer responsabilidades y obligaciones de transparencia a todos los actores, incluidos los usuarios en ciertos supuestos (co-diseño, personalización, uso comercial).
- Códigos éticos y autorregulación.
- Empresas y organismos públicos podrían establecer lineamientos internos y comprometerse a auditar periódicamente las salidas de la IA.
- Formación y certificaciones de usuario.
- Exigir cierta “formación mínima” para usuarios que operen IA en entornos críticos (salud, finanzas, jurídico, administración pública).
- Los proveedores de servicio de IA ponen a disposición de los usuarios herramientas tecnológicas para confeccionar los prompt de forma que sean mecanismos de ayuda para lograr las respuestas deseadas, este enlace se pone a disposición de los usuarios un mecanismo auxiliar para que puedan generar instrucciones eficaces que minimice condiciones vagas o defectuosas el enlace es: https://aistudio.google.com/prompts/new_chat
8.3. POLITICA PREVENTIVA PARA EVITAR LA ILUSIÓN DE LA INTELIGENCIA ARTIFICIAL Y SOLUCIONES DESDE LA CULTURA DE USO.
- Educación digital.
- Impulsar campañas sobre el riesgo de alucinaciones de la IA y la necesidad de contrastar y verificar datos.
- Alertas y avisos de contenido
- Implementación de metadatos y sellos en las respuestas generadas, advirtiendo sobre la necesidad de validación humana.
- Responsabilidad y prudencia
- Fomentar la idea de que el usuario y generador del prompt es la parte clave y fundamental del proceso y debe asumir el deber de “duda razonable” frente a cualquier respuesta no verificada.
Una vez que haya utilizado ese marco o plantilla para crear las instrucciones, revise detalladamente el resultado. Compruebe todos los contenidos generados por la herramienta de IA contrastando la información con fuentes fiables, científicas y actuales. Para esto el usuario debe chequear todo el proceso generativo buscando las fuentes mediante un motor de búsqueda, pedir a la IA que proporcione referencias bibliográficas o fuentes para poder determinar de dónde puede haber sacado la información y cotejarlas con los respectivos URL o links y si es posible, solicitar la opinión de un experto que confirme la veracidad de la información.
8.4 Como convertirse en un ingeniero de prompts calificado.
La ingeniería de prompts resulta esencial para personalizar las respuestas y orientar los resultados del modelo hacia los objetivos deseados, por ello se debe implementar el uso de estratégicas y técnicas para la creación de prompts de IA eficaces y mitigación de riesgos
Para el correcto ejercicio de una ingeniería de prompts se presenta una descripción, y recomendaciones en una tabla con secciones como estructura, recomendaciones y ejemplos para detallar temas clave sobre ingeniería de prompts y evitar las ilusiones.
Desarrollando la tabla
Estoy creando una tabla extensa en español con secciones como creación de prompts, estilos, manejo de alucinaciones, evaluación de salidas, riesgos y mitigaciones, entre otros temas clave.
A continuación se presenta una tabla integral que organiza los puntos más relevantes de todo el contexto, con énfasis especial en la redacción y manejo de prompts, la identificación y mitigación de alucinaciones, el desarrollo de casos de uso sólidos para IA generativa y las mejores prácticas para convertirse en un “perfecto ingeniero de prompts” con destreza en el manejo de la inteligencia artificial. Cada fila aborda un tema clave, resume sus puntos centrales y presenta recomendaciones específicas.
| TEMA / ASPECTO | DESCRIPCIÓN / PUNTOS CLAVE | RIESGOS / DESAFÍOS | RECOMENDACIONES / BUENAS PRÁCTICAS | EJEMPLOS / APLICACIONES |
| 1. Elementos de un Prompt Efectivo. | – Definir un objetivo claro de interacción con la IA. – Evitar la ambigüedad y usar lenguaje conciso. – Especificar estructura, formato, tono y/o estilo de la respuesta deseada. es decir, especificarle como se estructure la salida. – “Garbage in, Garbage out”: la IA es sensible a la calidad de las instrucciones. Sea especifico del motivo o causa de la necesidad de la consulta. | – Prompts vagos o ambiguos generan respuestas irrelevantes o erróneas. – Falta de contexto genera las alucinaciones o información incompleta. | – Ser específico en la instrucción o solicitud. – Incluir el número de elementos requeridos (p. ej., “Lista 5 puntos…”). – Proveer ejemplos si se desea imitar un estilo. – Aclarar previamente el formato de salida (lista de bu;;et, points, texto, tabla). – Revisar y refinar si el primer resultado no es suficiente o no lo convence. | – “Explica en 3 párrafos por qué la IA puede alucinar”. – “Enumera 4 ejemplos de chatbots corporativos con resultados exitosos”. |
| 2. Proceso de Redacción de Prompts. | – Paso 1: Definir tu meta y qué esperas obtener (información, análisis, explicación de la tarea a ejecutar, creatividad, etc.). Además indicarle las Alertas, es decir especificar precauciones y warnings de lo que no debe hacer la IA. – Paso 2: Redactar y probar el prompt. – Paso 3: Analizar la respuesta y compararla con la meta. Hacer un cruce de información de la entrada vs. la salida. – Paso 4: Iterar (hacer ajustes) hasta obtener la calidad deseada. | – Si se omite la fase de iteración, se corre el riesgo de quedarse con una respuesta superficial o inexacta. – Subestimar la importancia de volver a preguntar o profundizar con prompts de refinamiento. | – Iterar: no conformarse con el primer resultado. – Usar preguntas de seguimiento (“chain-of-thought”, “self-reflection prompts”). – Solicitar clarificaciones al modelo (“explica tu razonamiento describe todos los pasos seguidos que justifique tu respuesta”). | – Prototipos de prompts para análisis de riesgo en proyectos. – Refinamiento continuo para lograr textos publicitarios más persuasivos. |
| 3. Estilos y Enfoques de Prompt. | Existen varios enfoques según la meta: 1. Información (Information Retrieval): Zero-shot, one-shot, few-shot, entrevista. 2. Análisis y Reflexión: chain-of-thought, self-reflection, counterpoint. 3. Creatividad: role-playing, escenarios simulados, tree-of-thought. 4. Guía Instruccional: descomposición paso a paso, plantillas, narrativas guiadas. En el caso de cálculos o razonamientos complejos, indicar al modelo que dé pasos lógicos: “Primero analiza… luego revisa.. 5. Exploración Colaborativa: prompts conversacionales e iterativos. 6. Utilización de la técnica de interacción invertida (en vez de pedir soluciones a la IA, presentar el problema con restricciones para modelar el enfoque). | – No elegir el estilo adecuado retrasa el obtener la respuesta apropiada. – Usar un estilo “creativo” cuando en realidad se requiere “información factual o muy técnica” ello puede provocar inconsistencias o alucinaciones. | – Seleccionar el estilo de prompt con base en el objetivo y la complejidad del tema. – Mezclar estilos si se requiere (p. ej. iniciar con “chain-of-thought” y luego un “few-shot” con ejemplos). | – Information Retrieval para datos muy concretos: “ Por ejemplo: preséntame datos de ventas de 2022”. – Chain-of-thought para razonamientos complejos paso a paso. – Role-playing cuando necesitas ideas de marketing desde la perspectiva de un cliente. |
| 4. Manejo de Alucinaciones (Hallucinations) en la IA. | – La IA puede “inventar” respuestas o datos sin base real, es decir, las llamadas alucinaciones. – Suceden por sobregeneralización de datos incompletos, sesgados o de mala calidad. – También surgen si el prompt carece de contexto suficiente o si el modelo no está bien ajustado (fine-tuning). | – Toma de decisiones equivocada o con datos falsos. – Problemas legales, de reputación y desconfianza si se difunden respuestas falsas. | – Verificar fuentes y contrastar la respuesta con documentación o expertos. – Actualizar y recalibrar el modelo con datos confiables. – Implementar “self-reflection” o “chain-of-thought” para que la IA explique sus pasos. – Si se pide información sensible, usar prompts que exijan referencias o explicaciones detalladas. | – Chatbots que inventan políticas de devolución. – Generadores de texto que citan bibliografía inexistente. |
| 5. Evaluación y Validación de Respuestas de la IA. | – Pensamiento Crítico: comprobar exactitud factual, consistencia, confiabilidad, ausencia de sesgos. – Pensamiento Reflexivo: verificar relevancia para el objetivo, nivel de precisión, transparencia (explicación del razonamiento), y aspectos éticos, El usuario debe tomar en cuenta el sentido común y su intuición ante la respuesta del sistema de IA, incluso debatirla o utilizar la dialéctica. | – Confiar ciegamente en la IA sin validar las salidas, ello puede derivar en costos altos y consecuencias negativas. – Falta de transparencia: no se sabe cómo llegó la IA a una conclusión. | – Cross-check: Solicitar fuentes, datos y verificar su validez. – Aplicar un criterio de “sentido común” y experiencia propia. – Evaluar la alineación con objetivos de negocio. – Incluir retroalimentación de usuarios afectados. | – Respuestas sobre planes estratégicos (verificar en informes oficiales o con expertos). – Propuestas de productos nuevos (verificar costo, factibilidad). |
| 6. Factores de Factibilidad y Diseño de Casos de Uso (Use Case). | – Usar objetivos SMART (Specific, Measurable, Achievable, Relevant, Time-bound). – Revisar factores: costo vs. beneficio, viabilidad operativa, impacto en usuarios/clientes, escalabilidad, riesgos. – Vincular el uso de IA con objetivos de negocio (eficiencia, ingresos, experiencia cliente). | – Subestimar costos de integración, complejidad técnica, entrenamiento de personal. – Sobrevalorar la adopción del usuario sin estrategias claras. | – Planificar con métricas claras de éxito (ROI, reducción de tiempos, etc.). – Revisar calidad de datos y disponibilidad de equipo experto. – Empezar con un prototipo o piloto para validar antes de escalar. | – Chatbot de servicio al cliente con meta de reducir 30% de costos. – Análisis de datos para pricing dinámico enfocado en obtener un 10% de crecimiento. |
| 7. Riesgos y Mitigación en la Integración de IA. | – Riesgos comunes: datos insuficientes o poco fiables, alucinaciones, brechas de seguridad, falta de cumplimiento normativo, bias. – Gobernanza de IA: responsabilidad, transparencia y ética. – Importancia de la ciberseguridad y cifrado de datos para proteger información sensible. | – Daños reputacionales, pérdidas financieras, litigios legales. – Cascada de fallas en interdependencias con terceros (proveedores, APIs). | – Diseñar políticas de seguridad y privacidad robustas. – Monitorear y actualizar periódicamente el modelo y los parches de software. – Crear o involucrar comités de ética cuando el impacto sea amplio. – Fomentar la transparencia y cooperación con otras áreas y socios comerciales. | – Escándalos de chatbots que dan información ofensiva o ilegal. – Multas por incumplir regulaciones de privacidad. |
| 8. Ejemplos de Éxito y Fracaso en Chatbots y GenAI. | – Caso de éxito: RideBikes, Inc. hizo un chatbot con meta SMART (ahorro costos + adopción usuario). Invirtió en análisis financiero, datos adecuados y capacitación progresiva. – Caso de fracaso: TechSupport Inc. redujo personal rápido sin garantizar calidad de datos ni testeos. Terminó en costos legales y pérdida de clientes. | – Éxito: visión clara de ROI, pruebas iterativas, balance entre reducción de costos y satisfacción del cliente. – Fracaso: expectativas irreales, falta de validación y personal no capacitado. | – Éxito: planificar con tiempo, involucrar equipos de TI, gerencia, usuarios. – Fracaso: se evita con un plan de escalabilidad y soporte humano de respaldo. – Mejorar la transición entre chatbot y agentes humanos para dudas complejas. | – RideBikes redujo un 30% del personal paulatinamente y logró 40% de uso del chatbot. – TechSupport perdió 10% de clientes y afrontó demandas. |
| 9. Métricas y Monitorización del Uso de IA. | – Definir KPIs ligados a metas de negocio (por ej. disminución de tiempos de respuesta, mejoras en ventas, reducción de costes). – Recalibrar el modelo con datos nuevos y medir su precisión periódicamente. – Hacer seguimiento de indicadores de satisfacción de clientes. | – Sin métricas, no se puede saber si la IA cumple con su objetivo. – Falta de seguimiento continuo = posible degradación del rendimiento sin detección. | – Establecer un sistema de monitorización (dashboards, informes periódicos). – Definir métricas claras: Tasa de adopción, error rate, ROI, satisfacción del cliente. – Ajustar el modelo periódicamente para mantener la eficacia. | – Chatbot que mide el % de interacciones exitosas (resueltas sin intervención humana). – Generador de textos que mide CTR (Click Through Rate) en campañas de marketing. |
| 10. Escalabilidad y Adaptación Continua | – La IA debe escalar con el crecimiento de la empresa. – Revisar costos de infraestructura (cloud, servidores, mantenimiento). – Prever integración con sistemas heredados y futuros. | – Subestimar la demanda real y saturar los servidores = baja calidad de servicio y mala experiencia de usuario. – Falta de actualizaciones que dejen el modelo obsoleto. | – Planificar un crecimiento incremental: empezar con un MVP o piloto. – Revisar contratos con proveedores de cloud para ampliar capacidad ante picos de demanda. – Actualizar el modelo periódicamente y hacer auditorías de rendimiento. | – Escenario de e-commerce con picos en fechas especiales (Black Friday). – Sistemas de recomendación en sitios web con creciente número de usuarios. |
| 11. Gobernanza y Aspectos Éticos de la IA | – Gobernanza implica asegurar responsabilidad y transparencia. – Prever riesgos éticos: discriminación, sesgos, decisiones automatizadas que afecten a grupos vulnerables. – Importancia de la cooperación interdepartamental e información clara a los clientes. | – Falta de rendición de cuentas puede generar abusos y pérdidas reputacionales. – Normativas emergentes (RGPD, estándares de IA responsable, etc.) que exigen cumplimiento. | – Crear políticas y comités de IA para revisión ética. – Explicar a los usuarios cuándo interactúan con IA. – Establecer responsables claros (Roles de AI Governance). – Mantenerse actualizado en regulaciones y leyes emergentes. | – Empresas con “Chief AI Officers” o “comités de ética” que revisan algoritmos y resultados. – Transparencia en chatbots (“Soy un asistente virtual, no humano”). |
| 12. Conclusión y Recomendaciones Finales | – La clave para un uso exitoso de IA generativa es alinear las capacidades técnicas (prompting, datos, entrenamiento) con los objetivos de negocio. – La calidad de los prompts y la verificación de las respuestas son esenciales para evitar alucinaciones. – Invertir tiempo en un caso de uso sólido (con objetivos, métricas y plan de escalado). | – Adoptar la IA sin un plan o sin pruebas incrementales puede llevar a fracasos costosos. – Subestimar la importancia de la supervisión humana y la actualización del modelo deriva en respuestas obsoletas o engañosas. | – Combinar pensamiento crítico + “prompt engineering” adecuado. – Iterar, validar y reentrenar la IA según cambien los objetivos o los datos. – Mantener una visión integral: seguridad, escalabilidad, finanzas y experiencia de usuario. – Incluir “feedback loops” para mejorar continuamente. | – Programas de IA que comienzan con un proyecto piloto y se expanden gradualmente a toda la organización. – Chatbots que se integran con CRM y sistemas de analítica para medir el impacto real en el negocio. |
8.6 Puntos Clave y Consejos para ser un “Perfecto Ingeniero de Prompts”
- Conocer el objetivo: Antes de escribir cualquier prompt, entiende exactamente qué necesitas de la IA (datos, ideas, análisis, estilo, etc. puedes hace run preámbulo como complemento de la instrucción).
- Estructura clara: Indica con precisión la forma de la respuesta (lista, tabla, párrafos) y el tono (formal, creativo, resumido, etc.).
- Sumar ejemplos: Para guiar a la IA, puedes incluir uno o varios ejemplos (one-shot o few-shot prompting) que muestren el tipo de salida deseada.
- Iterar y refinar: Ajusta continuamente los prompts si la respuesta inicial no cumple tus expectativas. Las preguntas de seguimiento mejoran la calidad de la salida.
- Verificación constante: Aplica pensamiento crítico: valida la respuesta con fuentes confiables y examina la coherencia. Si se sospecha de alucinaciones, pide explicaciones al modelo.
- Actualización y mejora: Reentrena o ajusta el modelo con datos más recientes; los prompts también deben evolucionar al cambiar tus metas o el contexto.
Con estos esquemas puedes conseguir una visión estructurada de todos los temas relevantes del contexto y las recomendaciones más importantes para manejar prompts de manera efectiva, mitigar alucinaciones y desarrollar casos de uso sólidos de IA en tu organización. ¡Éxito en tu camino para convertirte en un experto en inteligencia artificial y prompt engineering.
8.6.1 Tabla de Clasificación y Descripción de Patrones de Prompt».
En conjunto, estos patrones ofrecen una guía de cómo estructurar y mejorar la comunicación con un sistema de inteligencia artificial, permitiendo un control más preciso tanto de la entrada como de la salida, así como de la consistencia y la calidad de la información generada.
| Categoría | Ejemplos de Patrones | Descripción General |
|---|---|---|
| 1. Input Semantics | – Meta Language Creation | Definir un lenguaje intermedio o etiquetas especializadas para guiar al modelo sobre cómo interpretar y procesar la información de entrada. Es una forma avanzada de indicar la semántica que se desea.Por ejemplo, la creación de un «meta-lenguaje» específico para instruir al modelo acerca de cómo queremos que entienda ciertos términos o cómo debe comportarse. |
| 2. Output Customization | – Output Automater – Persona – Visualization Generator – Recipe – Template | Técnicas que guían la forma de la respuesta.Incluye métodos para formatear o estructurar la respuesta generada por la inteligencia artificial. Algunos ejemplos son generar plantillas, automatizar ciertas secciones, forzar el uso de un estilo o “persona” específica, generar pasos de receta o visualizaciones. Por ejemplo: dar un estilo narrativo concreto, generar un diagrama de flujo (visualización), o forzar un formato de salida en forma de lista, tabla o pasos de receta. |
| 3. Error Identification | – Fact Check List – Reflection | Métodos para detectar y corregir errores en la respuesta del modelo. La “Fact Check List” asegura la veracidad y exactitud de los datos; la “Reflection” motiva al modelo a reconsiderar la respuesta para subsanar posibles faltas de consistencia. |
| 4. Prompt Improvement | – Question Refinement – Alternative Approaches – Cognitive Verifier – Refusal Breaker | Se centra en iterar y refinar la pregunta o la tarea que se le envía al modelo. Abarca desde reformular preguntas y proponer aproximaciones alternativas, hasta verificar coherencia o superar posibles limitaciones en las respuestas (por ejemplo, si el modelo se niega a contestar a ciertos temas volver a insistir “Question Refinement” permite reformular la pregunta para obtener mejores respuestas, mientras que “Refusal Breaker” busca evitar bloqueos cuando el modelo se niega a responder (bajo ciertas políticas y límites). |
| 5. Interaction & Context Control | – Flipped Interaction – Game Play – Infinite Generation – Context Manager | Interaction (Interacción): Combina formas de diálogo o formatos de juego con el modelo, generando prompts para mantener una conversación más dinámica (ejemplo: “Flipped Interaction”, “Game Play” o “Infinite Generation”). Context Control (Control de Contexto): Maneja explícitamente el contexto que el modelo utiliza, por ejemplo, estableciendo límites de qué puede y no puede responder o cambiar la forma en que se mantiene la memoria del diálogo (por ejemplo, a través de un “Context Manager”). |
8.6.2 “Tabla de Patrones Avanzados de Interacción con LLM: Intención, Motivación y Ejemplos”
Se presenta una tabla consolidada que incluye cada patrón, seguido de los elementos sugeridos: intención, motivación, estructura de la idea, ejemplo de implementación y consecuencias.
Además, se hace mención a posibles composiciones entre los patrones (por ejemplo, combinar Persona + Game Play, Visualization Generator + Template, etc.).
| Patrón | Intención | Motivación | Estructura de la Idea | Ejemplo de Implementación | Consecuencias / Combinaciones |
|---|---|---|---|---|---|
| Meta Language Creation | Crear un “lenguaje alternativo” o notación para interactuar de forma específica con el LLM. | Evitar confusiones y mantener orden cuando hay múltiples instrucciones o un formato muy estructurado. | Definir marcadores o etiquetas (p. ej. [COMANDO: ...]) para separar instrucciones de texto normal. | Usar etiquetas para comandos específicos: <INSTRUCCION>, <FORMATO>, etc. | – Aporta claridad y reduce ambigüedad. – Puede combinarse con Template para reforzar un formato único. |
| Output Automater | Generar scripts o automatizaciones para ejecutar las recomendaciones del LLM (p. ej. un script en Python). | Ahorro de tiempo y reducción de errores al no tener que repetir manualmente las instrucciones. | Transformar la salida del LLM en código o instrucciones ejecutables. | El LLM sugiere pasos y automáticamente se genera un script que los implementa (p. ej., un Python script con librerías específicas). | – Eficacia en tareas repetitivas. Se puede combinar con Fact Check List para verificar datos antes de ejecutar. |
| Flipped Interaction | Hacer que sea el LLM quien plantee preguntas para recopilar toda la información necesaria. | Profundizar en detalles que el usuario desconoce o pasa por alto; enriquecer el contexto. | El LLM inicia y lidera el proceso de indagación, preguntando paso a paso. | El LLM pregunta: “¿Tienes datos X?, ¿Necesitas Y o Z?”, etc., hasta formar una base sólida para la respuesta final. | – Ayuda a identificar requisitos ocultos. – Puede combinarse con Cognitive Verifier para dividir en subpreguntas y luego unificar. |
| Persona | Asignar un “rol” al LLM (revisor de seguridad, cientifico, experto legal, profesor, etc.) para orientar sus respuestas. | Conseguir un tono, estilo o perspectiva coherente y especializado. | Definir explícitamente: “Actúa como un analista de seguridad: tus respuestas deben centrarse en riesgos y mitigaciones.” | “Eres un profesor de matemáticas: explica la resolución de ecuaciones a nivel básico e intermedio.” | – Estilo y profundidad se adaptan al rol. – Combina bien con Game Play (juego de roles). |
| Question Refinement | Solicitar al LLM que reformule o mejore las preguntas para mayor exactitud. | Asegurar que la pregunta sea clara y se aborden posibles ambigüedades. | El LLM recibe la pregunta inicial y propone una versión mejorada o más detallada. | “¿Cómo podría mejorar mi pregunta para obtener un análisis más profundo de X?” | – Mejora la precisión de las consultas. – Se puede usar con Reflection para explicar por qué la nueva pregunta es más adecuada. |
| Alternative Approaches | Pedirle al LLM métodos o soluciones alternativas para una misma tarea, comparando ventajas y desventajas. | Evaluar opciones múltiples, facilitar la toma de decisiones más informadas. | El LLM ofrece varias soluciones, cada una con sus pros/contras y escenarios de uso. | “Dame al menos tres formas de resolver este problema de diseño, indicando costo, rapidez, escalabilidad, etc.” | – Visión más amplia de posibles soluciones. – Ideal para combinar con Output Automater y luego ejecutar cada opción en entornos de prueba. |
| Cognitive Verifier | Indicar al LLM que divida la pregunta en subpreguntas y luego combine las respuestas. | Aumentar precisión, asegurando que ningún detalle quede sin cubrir. | Estructurar la consulta en partes: introducción, detalles específicos, validaciones. | “Desglosa la pregunta ‘¿Cómo mejorar la seguridad de mi sitio web?’ en tres subpreguntas y luego integra las conclusiones en una respuesta final.” | – Menos riesgo de información incompleta. <br/> – Funciona bien con Fact Check List y Flipped Interaction. |
| Fact Check List | Incluir una lista de “hechos clave” que deben verificarse para asegurar la exactitud de la respuesta. | Reducir la propagación de errores o datos inexactos. | Proveer al LLM una lista de puntos a contrastar o confirmar antes de dar la respuesta final. | “Verifica si estos 5 puntos son correctos y coherentes con la respuesta que das sobre el tema.” | – Salida más confiable. – Compatible con Template para documentar cada punto verificado. |
| Template | Forzar un formato de salida muy específico, rellenando campos o secciones predefinidas. | Garantizar consistencia en informes, reportes o documentación estándar. | Definir una estructura fija (secciones, títulos, etc.) y solicitar que el LLM la complete. | “Llena este formato: \n1. Contexto \n2. Problema \n3. Solución Propuesta \n4. Pasos Detallados \n5. Conclusión” | – Facilita la lectura y el procesamiento automatizado. – Muy útil con Meta Language Creation para etiquetar secciones. |
| Infinite Generation | Repetir la generación de respuestas sin reescribir todo el prompt, aprovechando el contexto previo. | Agilizar iteraciones y refinamientos sucesivos de la respuesta. | Mantener el hilo de la conversación activo, solicitando al LLM nuevas versiones o variaciones. ejemplo respuestas alternativas. | “Continúa con más ideas basadas en las sugerencias previas, sin perder el contexto inicial.” | – Flujo continuo de ideas. Combinable con Reflection para evaluar cada versión antes de solicitar la siguiente. |
| Visualization Generator | Pedirle al LLM que genere texto como insumo para otra herramienta de visualización (Graphviz, DALL·E, etc.). | Facilitar la creación de diagramas, gráficos o imágenes a partir de descripciones textuales. | El LLM produce código o descripciones que luego se pegan en la herramienta de visualización. | “Genera un diagrama en lenguaje Graphviz que muestre la arquitectura de microservicios descrita.” | – Simplifica la comunicación de conceptos complejos. – Funciona muy bien con Template para formatear el output de manera específica. |
| Game Play | Crear una “dinámica de juego” a partir de un escenario o tema (p. ej., simular un ataque de ciberseguridad). | Aportar un método interactivo y lúdico para aprender o analizar situaciones complejas. | Definir roles, reglas y objetivos del juego; el LLM actúa como narrador o participante. | “Asume el rol de ‘atacante’ y yo seré el ‘defensor’; describe los pasos de tu ataque y cómo podría responder.” | – Favorece el aprendizaje práctico. Puede combinarse con Persona (juego de roles) y Reflection para analizar las estrategias. |
| Reflection | Indicar al LLM que explique sus razonamientos y suposiciones detrás de cada respuesta. | Entender el proceso de pensamiento y detectar posibles errores o sesgos. | Solicitar que, tras dar la respuesta, muestre una justificación clara de por qué eligió esos argumentos. | “Explica paso a paso cómo llegaste a esta conclusión y qué suposiciones hiciste en el camino.” | – Transparencia en la generación de respuestas. <br/> – Se integra bien con Question Refinement para mejorar las preguntas basadas en el razonamiento. |
| Refusal Breaker | Pedir al LLM que proponga alternativas o enfoques indirectos cuando no pueda responder algo directamente. | Evitar estancarse por restricciones o falta de datos. | Si el LLM rechaza una petición, se le solicita una vía legal, ética o parcial de solución. | “No puedes dar código malicioso, pero sí puedes explicar métodos de prueba. ¿Qué opciones legales hay para probar la seguridad sin infringir normas?” | – Facilita soluciones creativas cuando hay límites. – Útil con Flipped Interaction para que el modelo busque más info o nuevos enfoques. |
| Context Manager | Controlar qué información debe (o no) considerar el LLM, delimitando el alcance de la conversación. | Mantener el foco en los objetivos y evitar usar datos irrelevantes o confidenciales. | Declarar explícitamente la información disponible y la que está fuera de alcance. Tambien evita contextos demasiados extensos. | “Ignora todo lo referente a sistemas operativos antiguos; enfócate solo en Windows 11 y macOS Monterey.” | – Mayor pertinencia en las respuestas. – Se combina bien con Fact Check List y Persona para mantener el foco y la especialización adecuada. |
Notas sobre las Composiciones de Patrones (Punto 6):
- Puedes mezclar varios patrones para obtener resultados más complejos y personalizados.
- Ejemplos:
- Persona + Game Play: Crea un “juego de roles” donde cada participante (o personaje) tenga un perfil diferente.
- Visualization Generator + Template: Controla el formato de la salida y asegúrate de que sea compatible con la herramienta de visualización.
- Question Refinement + Reflection: Después de reformular la pregunta, el LLM explica su razonamiento paso a paso, enriqueciendo aún más la respuesta.
En cada patrón, los elementos clave (intención, motivación, estructura, ejemplo y consecuencias) ayudan a entender rápidamente su función y valor. De esta forma, es más sencillo combinar varios para adaptarlos a distintos contextos o casos de uso.
8.6.3 Tabla. Técnicas Clave de Prompting
| Técnica | Descripción | Aplicación / Ejemplo |
|---|---|---|
| Práctica e iteración | Dedicarse a experimentar con prompts, revisar la salida y refinar el enfoque de manera cíclica. | Escribir un cuento corto para entender cómo responde el LLM y, con esa experiencia, aplicarlo a tareas diversas. |
| Preguntar al LLM “cómo ser ‘prompteado’” | Consultar directamente al modelo qué tipo de instrucción o formato necesita. | “¿Cómo prefieres que te formule la información para generar un memo l de una determinada área?” |
| Few-Shot Prompt | Incluir ejemplos de entrada-salida para guiar al modelo en la forma y estilo deseados. | Mostrarle ejemplos de un memo ya escrito y pedirle “Imita esta estructura y este tono para el documento X.” |
| Chain-of-thought | Pedir explícitamente al modelo que razone paso a paso (para que acceda a un razonamiento más profundo). | “Desglosa cada aspecto del estatuto aplicable y explica cómo afecta al caso en orden lógico.” |
| Persona Prompt | Indicarle al LLM que asuma un rol o estilo específico (p.ej., “actúa como un asociado de primer año”). | “Eres un asistente recién contratado elabora un borrador del archivo siguiendo las siguientes pautas de formato.” |
| Refinar y retroalimentar | Revisar la respuesta, detectar errores u omisiones y reformular el prompt para subsanar esos puntos. | “Veo que omitiste la sección de análisis. Añádela, explicando la jurisprudencia relevante.” |
8.6.4“Tabla resumen de Buenas Prácticas para la Redacción, Evaluación y Gobernanza de Prompts”
| TEMA / ASPECTO | RECOMENDACIONES / BUENAS PRÁCTICAS |
|---|---|
| 1. Elementos de un Prompt Efectivo | • Ser específico, claro y conciso. • Incluir número y formato de la salida. • Proveer ejemplos de estilo. • Revisar y refinar según necesidad. • Incorporar explícitamente el marco Tarea‑Contexto‑Referencias‑Evaluar‑Iterar para guiar la estructura del prompt. • Asegurarse de que el Contexto sea suficiente (objetivos, público, restricciones) antes de enviar la solicitud. |
| 2. Proceso de Redacción de Prompts | • Definir la meta y las alertas. • Probar el prompt y analizar la respuesta. • Iterar hasta lograr la calidad deseada. • Añadir el paso Evaluar de forma explícita (¿cumple la respuesta el propósito, exactitud y tono?). • Documentar cada iteración para facilitar ajustes y aprendizajes futuros. |
| 3. Manejo de Alucinaciones | • Verificar fuentes y recalibrar el modelo. • Solicitar explicaciones paso a paso (chain‑of‑thought). • Exigir referencias cuando la información sea sensible. • Implementar una verificación previa de hechos (“Verificar y cotejar”) antes de aceptar la salida. • Reforzar el contexto suministrado para reducir lagunas que provoquen alucinaciones. |
| 4. Evaluación y Validación de Respuestas | • Comprobar exactitud factual y consistencia. • Solicitar fuentes y aplicar sentido común. • Evaluar alineación con objetivos de negocio. • Utilizar una lista de verificación basada en el paso Evaluar del marco de 5 pasos (propósito, precisión, tono, ética). |
| 5. Riesgos y Mitigación / Gobernanza | • Diseñar políticas de seguridad y privacidad robustas. • Monitorear y actualizar el modelo. • Involucrar comités de ética cuando sea necesario. • Respetar la privacidad: anonimizar datos sensibles dentro del prompt y las referencias. • Transferir las habilidades de prompting entre distintas plataformas (Gemini, ChatGPT, Copilot) para comparar outputs y elegir la solución más segura. |
| 6. Conclusiones y Recomendaciones Finales | • Alinear prompts, datos y entrenamiento con objetivos de negocio. • Verificar y reentrenar de forma continua. • Mantener supervisión humana. • Practicar la iteración como conversación constante, tal como lo indica el marco de 5 pasos. |
8,6.5 Tabla Marco Crear entradas cuidadosamente”
| Paso | Propósito | Claves prácticas | Ejemplo del texto |
|---|---|---|---|
| T ‑ Task | Indica con precisión qué debe hacer la IA. | • Añade persona (experiencia o audiencia) • Especifica formato (lista, tabla, párrafo, imagen). | “Eres crítico de cine italiano; crea una tabla con las mejores películas de los 70.” |
| C ‑ Context | Aporta trasfondo y restricciones para afinar la respuesta. | Metas, motivos, intentos previos, tono, público. | Ejemplo de ADN: se aclara objetivo docente y feedback de alumnos. |
| R ‑ References | Muestras o recursos que la IA debe emular. | 2‑5 ejemplos (texto, imagen, audio); explica su relación con la tarea. | Descripción del reloj basada en ejemplos de gafas y tarjetero. |
| E ‑ Evaluate | Verifica exactitud, relevancia, sesgos y formato. | Pregúntate: ¿cumple lo pedido? ¿Necesita ajustes? | Se insiste en comprobar datos antes de incorporar el resultado. |
| I ‑ Iterate | Refina el prompt hasta lograr el resultado ideal. | Ajusta detalles, divide tareas, cambia redacción, añade límites. | “ABI – Always Be Iterating” como mantra. |
8.6.6. Métodos de Iteración Destacados
| Método | Cómo se aplica | Beneficio |
|---|---|---|
| 1. Volver al marco T‑C‑R‑E‑I | Reescribir la petición añadiendo persona, formato, más contexto y referencias. | Mayor especificidad → respuestas más útiles. |
| 2. Dividir en frases cortas | Separar un prompt largo en subtareas secuenciales. | La IA procesa una tarea a la vez y reduce ambigüedad. |
| 3. Cambiar redacción o usar tarea análoga | Reformular la solicitud o pedir algo similar que active otro enfoque. | Desencadena ideas nuevas y evita repeticiones poco creativas. |
| 4. Introducir restricciones | Limitar por longitud, región, fecha, género, etc. | Obtiene resultados más focalizados y originales. |
8.6.7 Tabla Delimitadores para Mantener Claridad en los Prompts
| Delimitador | Uso principal | Ejemplo referido |
|---|---|---|
Triple comillas """ | Separar claramente secciones de texto. | Post de redes a partir de un anuncio entre comillas. |
Etiquetas XML <task> | Marcar inicios y finales de bloques complejos. | <task>Describe tu misión</task> |
Markdown (**, _) | Conservar formato (negritas, cursivas) al copiar en la IA. | **Título** para resaltar encabezados en texto plano. |
8.6.8 Otras Prácticas Generales y Checklist de Redacción de Prompts Profesionales.
| Acción | ¿Por qué? | Recordatorio rápido |
|---|---|---|
| A.Especifica la tarea con persona y formato. | Evita salidas vagas o irrelevantes. | “¿Qué debe entregar exactamente la IA?” |
| B Añade todo el contexto relevante. | Más datos ⇒ mejor ajuste a la necesidad. | No temas “sobre‑explicar”. |
| C.Proporciona referencias claras. | Orienta estilo y contenido. | 2‑5 ejemplos bastan. |
| D.Evalúa críticamente cada resultado. | Detecta errores, sesgos y vacíos. | Verifica hechos antes de usar. |
| E.Itera sin empezar de cero. | Pulir un prompt ahorra tiempo y mejora calidad. | ABI: Always Be Iterating. |
| 1 | Escriba el objetivo en una sola frase clara y medible. | El modelo necesita saber qué tiene que lograr para elegir correctamente entre alucinación creativa o precisión factual. | “Resume en 3 viñetas los riesgos de IA generativa para abogados corporativos.” |
| 2 | Añada el contexto relevante (audiencia, tono, dominio, limitaciones). | Sin contexto el modelo rellena huecos con suposiciones; contextualizar reduce alucinaciones inoportunas. | “Explica transformers a contadores sin formación técnica, usando analogías financieras sencillas.” |
| 3 | Declare explícitamente el formato deseado. | Obliga al modelo a organizar la salida; facilita verificación y reutilización. | “Devuélveme la respuesta en JSON con campos pregunta, respuesta, cita.” |
| 4 | Indique el rol o persona que debe adoptar. | Focaliza el tipo de detalles que ofrecerá (seguridad, UX, marketing…). | “Actúa como auditor de ciberseguridad y revisa este script Python.” |
| 5 | Pida siempre que explique su razonamiento y supuestos clave. | “Reflexión” ayuda a detectar errores y a mejorar el siguiente prompt. | “Explica paso a paso cómo llegaste a la conclusión y qué datos asumiste.” |
| 6 | Solicite una lista de hechos/afirmaciones que deban ser verificados. | Permite fact‑checking rápido; evita aceptar referencias inventadas. | “Al final, lista las 5 afirmaciones cruciales que debo comprobar.” |
| 7 | Si la tarea es compleja, pídale que genere preguntas aclaratorias antes de responder. | El modelo refina el problema (“Cognitive verifier”) y reduce malentendidos. | “Formula 3 preguntas que necesites contestar antes de proponer la estrategia.” |
| 8 | Cuando haya varias vías de solución, exija alternativas y comparativa. | Evita sesgos; fomenta elección informada (“Alternative approaches”). | “Propón 2 métodos distintos para desplegar en AWS y compara coste y mantenimiento.” |
| 9 | Limite el alcance y las fuentes si necesita precisión. | Reduce riesgo de información obsoleta o ajena a su dominio. | “Cita solo estudios revisados por pares desde 2022.” |
| 10 | Para tareas creativas, permita “alucinación” explícitamente y defina la temática. | La inventiva es útil cuando se busca variedad; delimitar tema evita divagaciones. | “Inventa 5 títulos de novela hard‑sci‑fi inspirados en neutrinos.” |
| 11 | Establezca criterios de riesgo y dile a la IA cuándo debe abstenerse de aconsejar. | Evita que la IA tome decisiones críticas sin contexto médico/legal. | “Si la respuesta implica salud o medicamentos, sugiere consultar a un profesional.” |
| 12 | Defina si el resultado será borrador o texto listo para uso. | Mantiene claro el grado de revisión humana necesario. | “Redacta un primer borrador de contrato; marcar ‘TODO’ donde falten datos.” |
| 13 | Para procesos repetitivos, describa una plantilla y los marcadores de posición. | Automatiza salidas consistentes (“Template”); minimiza edición manual. | “Usa la plantilla —CLIENTE, PROYECTO, COSTO— para cada propuesta.” |
| 14 | Finalice con una orden de verificación o de acción específica. | Asegura el siguiente paso (envío, revisión, codificación, etc.). | “Si el borrador tiene menos de 250 palabras, pídeme ampliar detalles.” |
Sugerencia rápida: antes de pulsar Enter, repase su prompt con la lista: Objetivo – Contexto – Formato – Rol – Riesgo – Verificación (OCFRRV). Si todos los puntos están cubiertos, la probabilidad de obtener una respuesta fiable y útil aumenta drásticamente.
8.6.9 🎯Guía de Prompts e Instrucciones para Generar Imágenes con IA Generativa
| OBJETIVO / CONSEJO | CÓMO APLICARLO EN UN PROMPT O INSTRUCCIÓN |
|---|---|
| ✅ Define claramente lo que deseas generar | “Genera una imagen de una guitarra eléctrica brillante para un cartel de rock.” |
| 🎯 Especifica el tipo de imagen o estilo visual | Usa frases como: “en estilo fotográfico”, “dibujado a mano”, “minimalista”, “realista”, “tipo ilustración”. |
| 🌈 Incluye detalles visuales vívidos | Agrega: colores específicos, textura (brillante, opaca), elementos de fondo (cielo, ciudad, bosque), etc. |
| 📏 Menciona la composición y la disposición de los elementos | Ejemplo: “El objeto principal debe estar en primer plano, centrado, y ligeramente inclinado hacia la izquierda.” |
| ✨ Usa palabras que inspiren emoción o atmósfera | “Debe transmitir energía y emoción, como si fuera una escena épica o de concierto en vivo.” |
| ⚡ Agrega elementos creativos para potenciar la imagen | “Añade rayos, chispas, humo o luces de neón detrás del objeto para hacerlo más impactante.” |
| 🔁 Itera sobre los resultados obtenidos | Si el resultado no convence, pide: “Haz que el fondo sea más oscuro y añade reflejos metálicos en el objeto.” |
| 🎨 Combina modalidades si es posible (texto + imagen de referencia) | Sube una imagen base y escribe: “Haz una versión más estilizada con los mismos colores y composición.” |
| 📌 Usa el marco de prompting T-C-R-E-I (Task, Context, References, Evaluate, Iterate) | Ejemplo: Task: imagen de portada, Context: afiche de concierto, References: estilo ochentero, Iterate: añadir público al fondo |
| 🚫 Evita ser demasiado genérico o vago | En vez de “haz una imagen bonita”, di: “crea una imagen colorida de un amanecer tropical visto desde una montaña con nubes naranjas.” |
✅ Recomendaciones y consejos clave para prompts efectivos ✅
- Especifica claramente el contexto (situación, público, objetivo).
- Detalla tu tarea y formato deseado en tu prompt.
- Utiliza referencias visuales o textuales para aclarar o reforzar tu petición.
- Divide tareas complejas en sub-prompts para facilitar su ejecución.
- No temas iterar y ajustar tu prompt según la respuesta recibida.
- Solicita mejoras explícitas («Leveling up») si la respuesta inicial no es suficiente.
- Combina diferentes prompts («Remixing») cuando ninguno por sí solo es completamente satisfactorio.
- Experimenta con distintos estilos y tonos para encontrar la respuesta más adecuada y atractiva («Style swap»).
📝 Consejos adicionales para optimizar tus prompts:
✅ Usa lenguaje natural y claro para mejores resultados.
✅ Sé explícito sobre la intención y resultado esperado en tu petición.
✅ Incluye ejemplos si es posible, para guiar con más precisión a la herramienta.
✅ Siempre realiza una evaluación crítica de la respuesta obtenida para mejorar futuras iteraciones.
✅ Mantener registro de prompts efectivos
Guardar los prompts que han demostrado buenos resultados para reutilizarlos.
✅ Usar Prompt Versioning
Registrar diferentes versiones de un mismo prompt para evaluar y mejorar resultados.
✅ Crear una biblioteca organizada
Nombrar y almacenar prompts en una biblioteca personal para facilitar su acceso posterior.
✅ Reutilizar y adaptar prompts exitosos
Ajustar prompts existentes cambiando contexto, tono, formato o audiencia sin empezar desde cero.
✅ Experimentar constantemente
Explorar variaciones en tareas, contextos y referencias para obtener diferentes resultados.
✅ Participar en comunidades de prompts
Aprender de las experiencias exitosas de otros usuarios para descubrir nuevas técnicas.
✅ Ajustar el tono y formato según la audiencia
Modificar un mismo prompt adaptándolo al perfil específico del público objetivo.
Estas tablas, recomendaciones y sugerencias, condensan los puntos esenciales cómo estructurar prompts efectivos tanto para textos como imágenes, son métodos de iteración con la IA para perfeccionar resultados y los recursos prácticos (delimitadores y buenas prácticas) que maximizan el valor de cualquier herramienta de IA generativa y minimizan los riesgos de la Ilusion.
”8.6.10 “PRINCIPIOS Y PATRONES PARA FILTRADO Y CITAS CON IA GENERATIVA”
| # | Idea / Patrón (español) | Qué significa en la práctica | Por qué es importante (según el contexto) |
|---|---|---|---|
| PRINCIPIOS GENERALES PARA FILTRAR Y CITAR | |||
| 1 | Filtrar solo contenido al que el usuario ya tiene acceso | El modelo trabaja sobre textos/datos suministrados por el propio usuario | Evita convertir la IA en “portero” que decide quién puede ver qué información |
| 2 | Separar el control de acceso del filtrado | Un sistema distinto (p. ej. políticas de permisos) decide visibilidad; la IA solo procesa | Reduce riesgos legales/éticos al mezclar funciones |
| 3 | No usar la IA para publicar o censurar hacia fuera | El filtrado está pensado para uso interno y apoyo cognitivo | Protege la confidencialidad y previene filtraciones accidentales |
| 4 | Objetivo = apoyar el razonamiento humano, no sustituirlo | La IA entrega listas, resúmenes, explicaciones; la decisión final sigue siendo humana | Cumple el principio de “human‑in‑the‑loop” del curso |
| 5 | Mantener trazabilidad (n.º de línea, IDs, citas) | Cada fragmento filtrado o resumido va enlazado a su origen | Facilita el fact‑checking y la auditoría |
| 6 | Resumir o explicar es válido solo si conserva trazabilidad | Después de cada frase de resumen se citan los IDs originales | Permite comprobar que no se invente contenido |
| 7 | Evitar filtrados donde un error cause daño posterior | Ej. diagnóstico médico automático sin verificación | Rompería la regla de “easy‑to‑check / low‑risk” |
| 8 | Filtrado ≈ operación segura: salida ⊆ entrada | El subconjunto se verifica rápido contra el documento fuente | Minimiza alucinaciones y falsos positivos |
| 9 | No pedir resúmenes “a ciegas” sin proveer la fuente | El modelo necesita texto base para citar | Petición sin contexto genera respuestas pobres o inventadas |
| 10 | La IA debe dirigir al experto (p.ej. médico) cuando el riesgo es alto | En lugar de dar consejo directo de salud | Mantiene la responsabilidad en el profesional humano |
| 11 | Filtrado bien diseñado = oportunidad “apasionante” | Procesa grandes volúmenes y extrae lo relevante | Multiplica la productividad sin sacrificar transparencia |
| PATRONES DE PROMPT PARA FILTRAR | |||
| P1 | Patrón de filtrado simple “Filtra X para incluir/eliminar Y” | Recorta listas o textos según un criterio claro | Más rápido y fácil de verificar |
| P2 | Patrón de filtro semántico 1) “Filtra para eliminar X” 2) “Explica qué y por qué” 3) “Devuelve IDs + texto filtrado” | Añade justificación + conserva identificadores de origen | Combina trazabilidad y transparencia |
| P3 | Patrón “Resume y cita” “Resume puntos clave y, tras cada frase, cita los IDs que la respaldan” | Genera síntesis verificable línea a línea | Permite lectura rápida sin perder rastro del dato fuente |
Uso recomendado: aplicar estos principios y patrones cuando necesite depurar grandes bloques de información (p.ej. revisiones legales, resultados de búsqueda, logs) y requiera demostrar de dónde proviene cada dato filtrado o resumido
8.7. Conclusiones y Sugerencias:
El riesgo de alucinación (hallucination) se reduce al proporcionar suficiente contexto e información antes de resolver.
El Patrón de Interacción Invertida es esencial para que la IA pregunte primero al usuario su rol, preferencias u otros datos clave.
Personalizar la experiencia (habilitar FAQ,- estilo de respuesta, menús de acciones) enriquece la interacción y evita respuestas genéricas o equivocadas. Es de recordar que la metodología de «Frequently Asked Questions», que en español se traduce como «Preguntas Frecuentes». Se trata de un listado en el que se recopilan las preguntas más comunes junto con sus respuestas sobre un tema específico. Este recurso se utiliza para:
a) Organizar la información: Al agrupar las dudas frecuentes en un mismo lugar, se simplifica la consulta y se mejora la experiencia del usuario.
b) Facilitar el acceso a información importante: Permite a los usuarios encontrar respuestas a dudas recurrentes sin necesidad de solicitar asistencia personalizada.
c) Ahorrar tiempo: Tanto para quienes buscan información como para quienes brindan soporte, al evitar responder individualmente preguntas que ya han sido contestadas.
Siempre se recomienda validar la información, citar documentos, y eventualmente redirigir al usuario a un contacto humano si hay ambigüedades.
Con estas técnicas, se aprovecha el potencial de la IA generativa para ayudar sin caer en alucinaciones ni ofrecer soluciones descontextualizadas. La clave reside en preguntar primero y adaptar las respuestas según la identidad y preferencias del usuario, así como documentar y respetar políticas actualizadas.
Tabla: Recomendaciones Finales
| Recomendación | Descripción / Justificación |
|---|---|
| Mantenerse al día con la evolución de la IA | Los LLM avanzan rápido; lo que hoy es limitación puede resolverse pronto. Investigar nuevas herramientas (fine-tuning, RAG, búsquedas integradas, etc.). |
| Usar salvaguardas para info confidencial | Si es un modelo público, la información que envíes puede tener un destino no seguro y verse comprometida. Utilizar soluciones que garanticen privacidad y cumplimiento de normativa (p.ej., versiones empresariales o “on-premise”). |
| Validar siempre la información con expertos en el área. | Un humano experimentado debe supervisar la salida del LLM, especialmente en cualquiera que sea el ámbito de investigación, para evitar errores o alucinaciones. |
| Emplear LLM como complemento, no reemplazo | El LLM es muy útil para borradores iniciales, brainstorming, resúmenes y apoyo creativo. Pero la revisión, la estrategia y propósito final siguen siendo responsabilidad humana. |
| Practicar con tareas no críticas al inicio | Antes de usar un LLM para un asunto de alta relevancia, practicar con ejemplos y ejercicios de menor riesgo para comprender sus fortalezas y debilidades. |
9.–ILUSIONES Y CONTRAINTELIGENCIA..
Las ilusiones de la IA —o alucinaciones— pueden producir daños reales en personas, empresas e instituciones. Aunque el desarrollador y el proveedor del modelo de IA desempeñan un papel crucial en la calidad y en la corrección de las salidas de la IA, el usuario no queda exento de responsabilidad por emitir prompts defectuosos o maliciosos.
- En el ámbito civil, se le puede exigir indemnización por daños y perjuicios cuando su imprudencia o negligencia cause un daño a terceros, o incluso cuando actúe de forma dolosa.
- En el ámbito penal, puede responder por delitos de calumnia, injuria, discriminación o difusión de contenidos ilícitos incitación al odio, si se demuestra su participación intencional o un grado de culpa relevante.
También se debe considerar para mitigar estas situaciones:
- Mejora tecnológica (modelos cuánticos de validación, XAI, fact-checking automático).
- Adecuada regulación y cláusulas contractuales (definir claramente la responsabilidad de cada parte).
- Cultura de uso responsable (educación, concienciación y sentido crítico).
Otras soluciones técnicas y humanas:
- Uso de fuentes verificadas: Implementar estrategias de Retrieval-Augmented Generation (RAG) combinando el modelo con bases de datos documentales como Weaviate, Pinecone o ChromaDB.
- Validación cruzada: Comparar la salida del modelo con múltiples fuentes antes de entregar la respuesta.
- Uso de embeddings personalizados: Utilizar embeddings generados con LangChain para mejorar la precisión en tareas específicas.
- Empleo de métricas que reflejen su rendimiento en el contexto previsto del uso previsto lo que determina una evaluación completa y significativa del modelo de IA.
- Uso de retrieval-augmented generation (RAG) con bases de conocimiento confiables.
- Implementación de modelos híbridos que combinen LLMs con sistemas de búsqueda semántica.
- Aplicación de post-procesamiento y validación humana para respuestas críticas.
- Uso de prompt engineering avanzado para mejorar la precisión de las respuestas.
- Evitar el uso de generalizaciones excesivas a partir de contextos de datos con errores o sesgos.
- Infraestructura híbrida: Despliegue de modelos en servidores locales y en la nube con equilibrio de carga inteligente.
- Para proyectos de inversión y trading algorítmico, combinar LangChain con técnicas de computación cuántica y simulaciones puede mejorar la eficiencia en cálculos complejos sin aumentar excesivamente los costos.
- No olvidar el empleo del juicio humano, con sus aportes de subjetividad, conciencia del contexto e interpretabilidad en el proceso de evaluación, en aras de garantizar la confiabilidad, la equidad, la usabilidad y la alineación del modelo de IA con las necesidades del mundo real. Sin lugar a dudas el criterio humano evaluará las implicaciones del modelo para la toma de las decisiones y de sus consecuencias.
Con un enfoque integral podremos avanzar hacia una IA confiable y humanamente beneficiosa, reduciendo al mínimo el riesgo de alucinaciones y propiciando un entorno donde la IA sea vista como una herramienta potente, pero siempre con supervisión y responsabilidad humana.
LA CONTRA INTELIGENCIA ARTIFICIAL.
El término “Contrainteligencia Artificial” (a veces llamado “contrainteligencia asistida por IA” o “counter-AI”) puede entenderse como el uso de técnicas, estrategias y herramientas basadas en la inteligencia artificial para llevar a cabo o reforzar acciones de contrainteligencia. En otras palabras, se refiere a la aplicación de métodos avanzados de análisis de datos, aprendizaje automático, procesamiento de lenguaje natural, entre otros, con el objetivo de:
- Proteger activos o información sensible: detectar y prevenir intrusiones, espionaje, filtraciones de datos o cualquier acción que comprometa la seguridad de una organización, estado o institución.
- Identificar y neutralizar amenazas: rastrear, analizar y anticipar comportamientos sospechosos (por ejemplo, ciberataques, infiltración de redes, manipulación de sistemas) con la finalidad de contrarrestarlos a tiempo.
- Analizar grandes volúmenes de información: la IA puede procesar masivamente datos de diferentes fuentes (redes sociales, comunicaciones cifradas, bases de datos gubernamentales, etc.) para encontrar patrones de riesgo o amenazas potenciales.
- AUTOMATIZAR LA VIGILANCIA Y LA RESPUESTA AL PROMPT.
En la práctica, la contrainteligencia se ha concebido tradicionalmente a través de métodos humanos de espionaje y contraespionaje (identificar infiltrados, desplegar agentes dobles, proteger redes de comunicaciones, etc.). Pero en este sentido tecnológico al incorporar IA, se potencia mas bien en este sentido:
- Analizar grandes flujos de datos.
- Detectar anomalías (por ejemplo, comportamientos de usuarios dentro de redes).
- Predecir futuros intentos de intrusión o sabotaje.
- Implementar una capacidad adicional de Defender, proteger y anticiparse al uso culposo o malintencionado de información y sistemas digitales (incluyendo IA), mediante la aplicación de tecnologías y metodologías de inteligencia artificial que proporcione una verificación de las salidas idóneas de respuestas a los prompt.
12.-ECUACIONES Y SUGERENCIAS DE CÓDIGOS:
10. Fundamentos Teóricos, Ecuaciones y Códigos.
Fidelidad Cuántica.
Para dos estados puros ∣ψ⟩y ∣ϕ⟩, la fidelidad se define como :
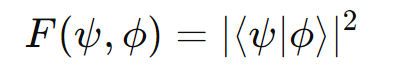
Esta medida cuantifica la “proximidad” o solapamiento entre ambos estados.
Swap Test
El swap test es un método para estimar la fidelidad sin conocer completamente los estados. Se utiliza un qubit ancilla y el operador controlado de intercambio (CSWAP). El circuito se construye de la siguiente forma:
- Inicializar el qubit ancilla en ∣0⟩| y aplicarle una compuerta de Hadamard, generando
Inicializar los qubits que almacenarán ∣ψ⟩ y ∣ϕ⟩ en los registros correspondientes.
Aplicar la compuerta CSWAP, de forma que se intercambian los estados de los qubits ∣ψ y ∣ϕ⟩ si el ancilla está en ∣1⟩
Aplicar otra Hadamard al ancilla y medirlo. La probabilidad de obtener el estado ∣0⟩ es
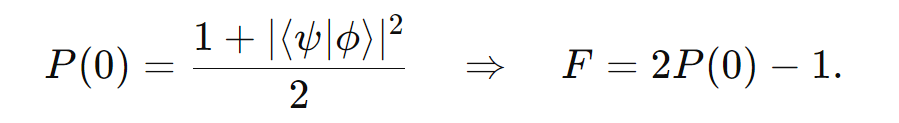
De donde se puede despejar la fidelidad:
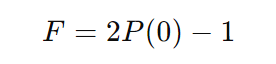
Fórmula de la Prueba de Intercambio (Swap Test): Para dos estados puros |ψ⟩ y |ϕ⟩, la probabilidad de medir el qubit ancilla en |0⟩ es:
P(0) = (1 + |⟨ψ|ϕ⟩|^2) / 2
Por lo tanto, la fidelidad F = |⟨ψ|ϕ⟩|^2 se obtiene como:
F = 2P(0) – 1
Esta ecuación se ha incorporado en el código de la prueba de intercambio para estimar la fidelidad.
Explicación:
- La prueba de intercambio se utiliza para medir la similitud entre dos estados cuánticos |ψ⟩ y |ϕ⟩.
- La probabilidad de medir el qubit ancilla en el estado |0⟩ está dada por: P(0) = (1 + |⟨ψ|ϕ⟩|^2) / 2
- La fidelidad F, que cuantifica la superposición entre los dos estados, se calcula como: F = |⟨ψ|ϕ⟩|^2 = 2P(0) – 1
- Esta relación nos permite estimar la fidelidad midiendo la probabilidad P(0) en la prueba de intercambio.
Estas ecuaciones son importantes para implementar la prueba de intercambio en algoritmos cuánticos y para analizar la similitud de estados cuánticos. Se proporciona una forma práctica de evaluar la cercanía de los estados cuánticos en diversas aplicaciones de computación cuántica.
Protocolo BB84
El protocolo BB84 es uno de los esquemas más estudiados para la distribución de claves cuánticas. Su funcionamiento se resume en:
- Preparación:
Alice genera bits aleatorios y selecciona bases aleatorias (por ejemplo, la base Z o la base X) para preparar los qubits. - Medición:
Bob elige aleatoriamente una base para medir cada qubit recibido. - Tamizado (Sifting):
Tras la comunicación pública de las bases (sin revelar los bits), se retienen únicamente aquellos casos en que las bases de Alice y Bob coinciden, generando así una clave compartida.
Código Primario:
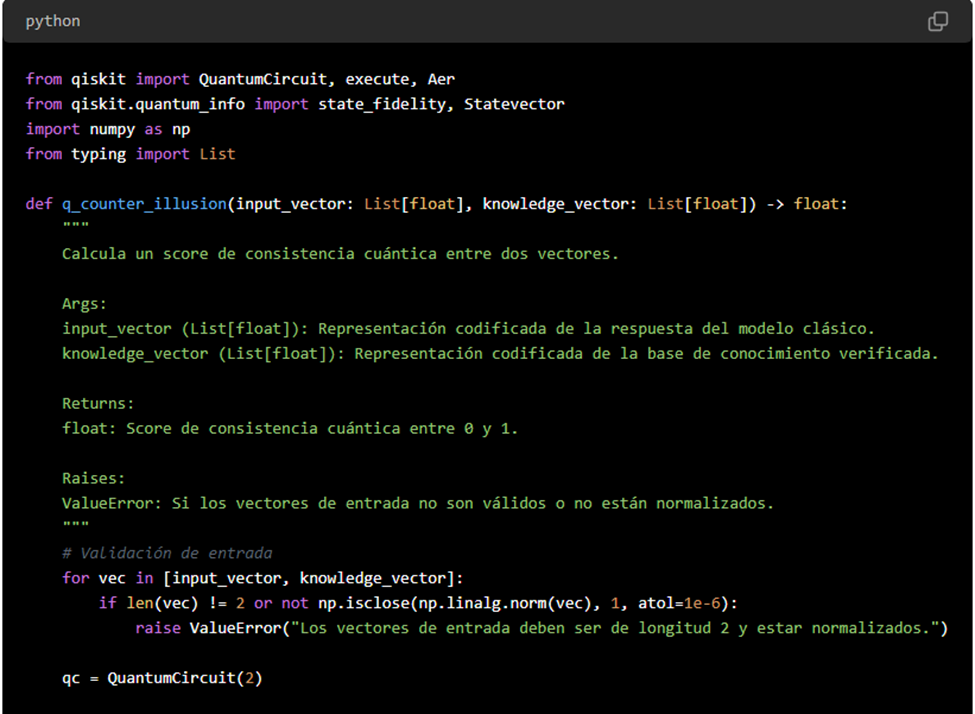
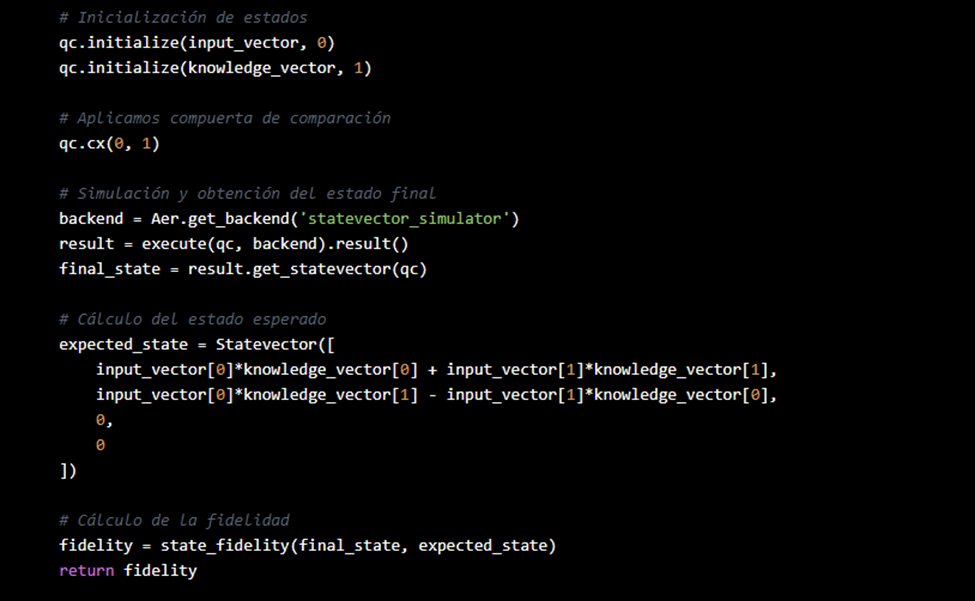
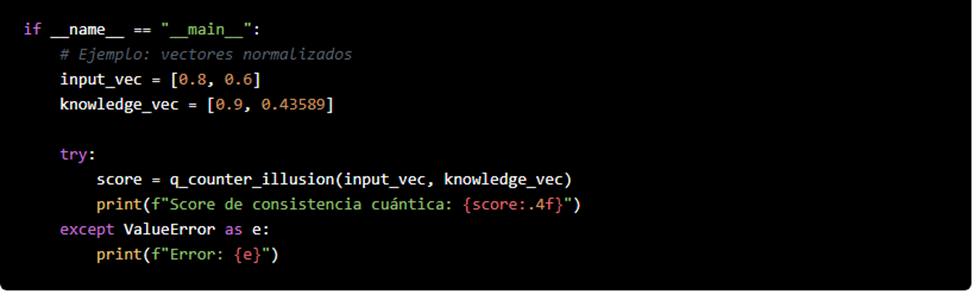
Otra versión:
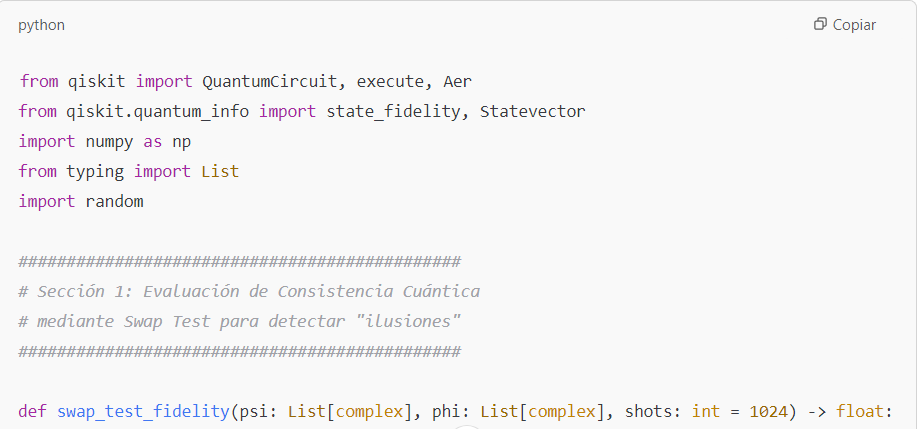

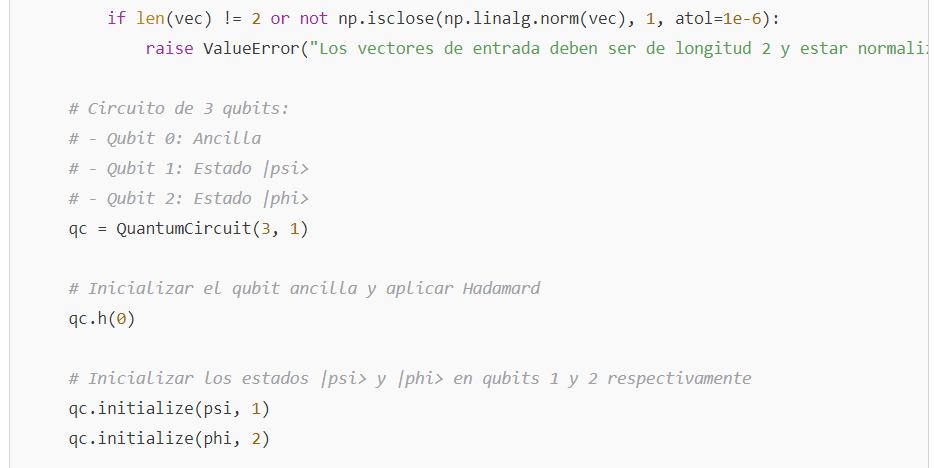





11. Integración de módulos cuánticos para verificación de IA.
Explicación y Aplicación:
Sección de Consistencia Cuántica.
- Objetivo: Medir la similitud entre dos representaciones (por ejemplo, la respuesta de un modelo de IA y una base de conocimiento verificada) usando el swap test.
- Implementación:
- Se construye un circuito de 3 qubits donde el qubit ancilla controla la operación de intercambio entre los registros de los dos estados.
- Se mide el ancilla para obtener P(0) y, mediante la relación F=2P(0) /1F = 2P(0) – 1, se estima la fidelidad entre los estados.
Esta técnica puede emplearse, por ejemplo, para detectar “ilusiones” en respuestas de IA al comparar la salida del modelo con una representación basada en conocimiento validado y actual.
Sección de Encriptación Cuántica (BB84)
- Objetivo: Simular el protocolo de distribución de claves BB84, que se utiliza para generar una clave secreta compartida mediante la preparación y medición de qubits en bases aleatorias.
- Implementación:
- Alice prepara qubits de acuerdo a bits y bases aleatorias.
- Bob mide cada qubit en una base aleatoria.
- Se realiza el “sifting” para retener solo aquellos casos en que las bases de preparación y medición coinciden.
El resultado es una clave compartida que, teóricamente, es segura contra interceptaciones gracias a las propiedades de la mecánica cuántica. Esta modalidad mitigaría ciberataques que pueden deformar la salida o respuesta de la IA. (SE CONTEMPLA EL CASO QUE EL ATAQUE SEA PROPICIADO POR OTRA IA).

Conclusiónes:
Este código mejorado integra dos componentes cruciales:
- Medición de consistencia cuántica mediante el swap test:
Proporciona un método robusto para validar la veracidad de información comparando estados cuánticos, lo que resulta muy útil para contrarrestar las “ilusiones” o alucinaciones de la IA. - Protocolo BB84 para encriptación cuántica:
Ilustra los principios fundamentales de la seguridad cuántica y la distribución de claves, ofreciendo una base para el desarrollo de aplicaciones de contrainteligencia artificial que requieran comunicaciones seguras y verificables.
Integración de Módulos Cuánticos en la Verificación de Sistemas de Inteligencia Artificial.
La propuesta de implementar un módulo de verificación cuántica —como el Q‑CounterIllusion— constituye un avance paradigmático que explota la capacidad de los circuitos cuánticos para evaluar la “consistencia cuántica” de las respuestas generadas por sistemas de inteligencia artificial tradicionales. Mediante la aplicación de técnicas avanzadas, como el swap test y la medición de fidelidad, este software opera como un filtro de alta precisión, identificando discrepancias entre el output del modelo generativo y un corpus de conocimiento validado. Este enfoque refuerza la robustez del sistema frente a los sesgos y errores inherentes a los modelos de lenguaje, al tiempo que proporciona un mecanismo de retroalimentación y corrección continua, reduciendo de forma significativa las alucinaciones.
También se puede considerar la integración de tecnologías emergentes (por ejemplo, blockchain para la trazabilidad, smart contracts para cláusulas de verificación automática que registren y auditen la veracidad de las salidas, reforzar las arquitecturas de redes neuronales, y frameworks de Quantum Machine Learning) y proporcionando ejemplos de implementación práctica (código en Qiskit, simulaciones en Python, etc.).
Retos: Los algoritmos cuánticos para el fact-checking todavía están en etapas tempranas de desarrollo y requieren una gran cantidad de qubits, para el proceso de incremento de estos véase el trabajo de investigación:
Ejemplo práctico: Implementación de un módulo de validación cuántica en Python utilizando Qiskit para ejecutar un swap test real.



Este ejemplo permite visualizar cómo se puede implementar el swap test para comparar dos estados cuánticos y, por ende, evaluar la “consistencia cuántica” de la información.
1. Código Mejorado para el Swap Test
El swap test se utiliza para estimar la fidelidad entre dos estados cuánticos. En este ejemplo, se utiliza una función para preparar los estados y se construye un circuito que implementa el swap test:
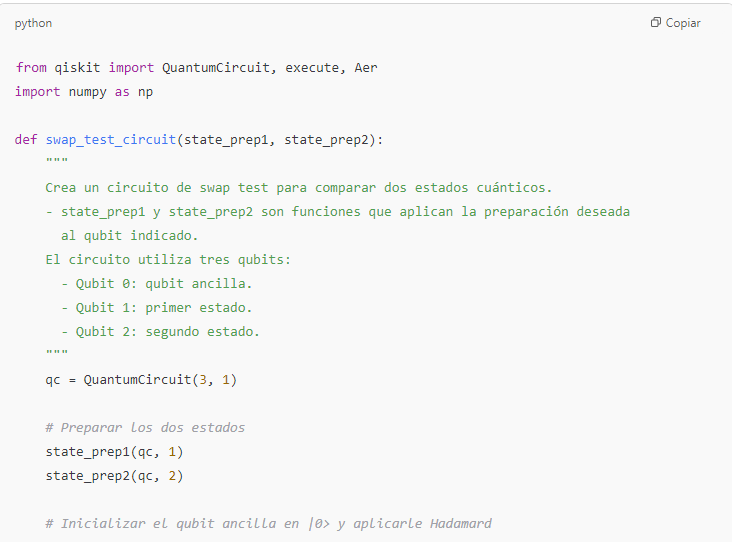
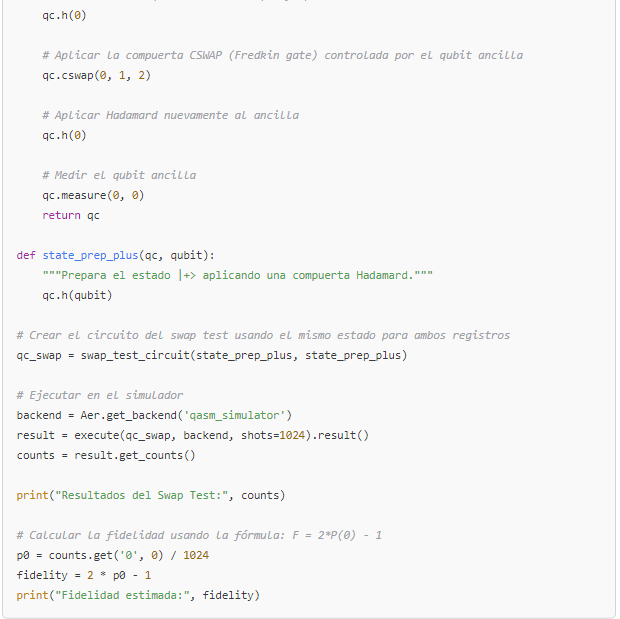
Nota:
La compuerta cswap (o compuerta Fredkin) está implementada en Qiskit y permite realizar el swap controlado. Este código es totalmente ejecutable en un entorno con Qiskit instalado.
2. Código Mejorado para una Simulación Simplificada del Protocolo BB84
El siguiente ejemplo simula de forma sencilla el protocolo BB84, donde Alice prepara qubits en bases aleatorias y Bob mide en bases aleatorias. Se realiza el proceso de «sifting» para extraer la clave compartida:


Explicación:
- Preparación: Alice genera bits y selecciona aleatoriamente una base (‘Z’ o ‘X’) para cada qubit.
- Medición: Bob también selecciona aleatoriamente una base y mide el qubit.
- Sifting: Se comparan las bases públicamente (sin revelar los bits) y se retienen aquellos bits donde las bases coinciden, formando la clave compartida.
Implicaciones Legales, Éticas y de Responsabilidad en la Era Híbrida.
El fenómeno de las “alucinaciones” en la inteligencia artificial va más allá de un mero desafío tecnológico, planteando serias interrogantes éticas y legales. Casos documentados —como la generación de citas jurisprudenciales inexistentes o errores críticos en el ámbito médico— evidencian los riesgos de difundir información errónea y resaltan la responsabilidad compartida entre desarrolladores y usuarios. La integración de mecanismos de verificación cuántica no solo mejora la calidad técnica de las respuestas, sino que también fortalece la trazabilidad y autenticidad de la información. Esto facilita una correcta atribución de responsabilidades en contextos civiles y penales, subrayando la necesidad de adoptar políticas preventivas, reforzar la ingenieria de prompts, aplicar los protocolos de verificación obligatoria y programas de educación orientados al uso responsable de la tecnología.
12.-Perspectivas Futuras y Estrategia de la Contrainteligencia Artificial como una medida de Defensa Cuántica y Verificación Híbrida en la IA.
A corto y mediano plazo, se anticipa la incorporación de módulos de contrainteligencia artificial en las herramientas de IA, lo que permitirá generar respuestas coherentes y seguras incluso ante prompts defectuosos o maliciosos, erradicando progresivamente las alucinaciones. La sinergia entre técnicas cuánticas e inteligencia artificial, enmarcada en aspectos de seguridad avanzada criptográfica y validación de contenidos, sienta las bases para una estrategia integral de contrainteligencia artificial. Esta estrategia no solo busca anticipar y detectar vulnerabilidades, sino que actúa de forma preventiva para corregir las “ilusiones” generadas por los sistemas de IA. El desarrollo de módulos híbridos como el Q‑CounterIllusion, sustentado en fundamentos teóricos sólidos —incluyendo la fidelidad cuántica, el swap test y protocolos de encriptación como el BB84—, ofrece una solución integral que protege la integridad de la información y garantiza un uso ético y legal de la tecnología.
Hacia un Futuro de Confiabilidad y Seguridad en la IA.
La integración de la computación cuántica en la verificación y validación de respuestas de sistemas de inteligencia artificial propone un camino innovador para erradicar las alucinaciones en los modelos generativos actuales. Aunque la tecnología cuántica aún se encuentra en fase de desarrollo, su eventual aplicación en módulos de verificación posibilita establecer un “filtro de consistencia” en tiempo real, capaz de detectar y corregir errores de manera efectiva, lo que refuerza la confiabilidad y seguridad de los sistemas de IA. Paralelamente, esta sinergia fomenta la creación de un marco regulatorio y de responsabilidad compartida, orientado hacia un uso seguro, transparente y ético de la inteligencia artificial en sectores críticos.
En definitiva, la convergencia de estos avances tecnológicos y jurídicos no solo fortalece la seguridad y la veracidad de la información, sino que también sienta las bases para una nueva generación de sistemas inteligentes. Respaldados por métodos de verificación cuántica, estos sistemas telemáticos se orientan hacia un futuro en el que la confianza en la IA sea verdaderamente sustentable y libre de “ilusiones”. Esta aproximación híbrida resulta especialmente relevante en contextos donde la precisión y la seguridad son críticas, dotando a desarrolladores y usuarios de herramientas sofisticadas que integran los beneficios de la computación cuántica tanto en la verificación como en la encriptación de datos sensibles.
Esta estrategia híbrida es crucial para garantizar precisión y seguridad en aplicaciones críticas, ofreciendo un marco robusto para el uso ético y responsable de la inteligencia artificial.
13.-Ventajas de generar un código soportado en tecnología cuántica para combatir las ilusiones de la inteligencia artificial.
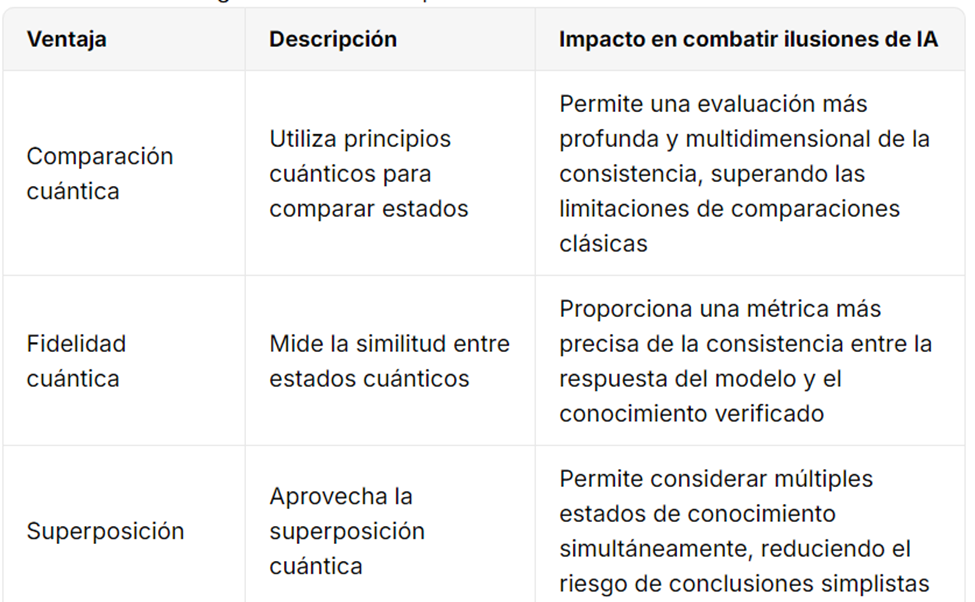
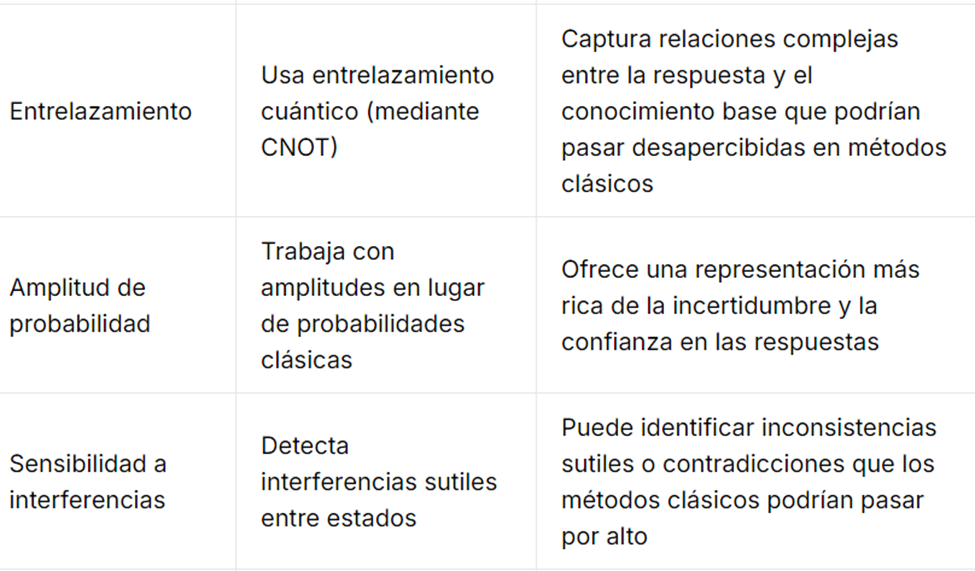

Esta tabla muestra cómo las propiedades únicas de la computación cuántica, implementadas en el código, lo cual puede ofrecer ventajas significativas para detectar y mitigar las ilusiones o inconsistencias en las respuestas de los sistemas de IA.
Entre la Ley y la Innovación: El Rol Protagónico del Juez en la Era de la Inteligencia Artificial:
| Aspecto | Conclusión / Implicaciones | Rol Protagónico del Juez |
|---|---|---|
| Desafíos de la IA en el Derecho | La irrupción de la inteligencia artificial plantea desafíos inéditos al introducir el riesgo de decisiones basadas en datos falsos o sesgados. | Debe mantenerse vigilante ante manipulaciones y validar rigurosamente las pruebas presentadas. |
| Dilema de la Responsabilidad | Se debate si la responsabilidad recae en los desarrolladores o proveedores de la IA, o en el usuario que genera el prompt que actúa fraudulentamente o por impericia. | El juez debe interpretar la ley de manera equilibrada y distribuir la responsabilidad en toda la cadena de producción y uso de la información. |
| Necesidad de Mecanismos de Control | Es imprescindible establecer correctivos que penalicen tanto a los actores maliciosos (litigantes o generadores de prompts defectuosos) como a posibles fallos sistémicos. | El órgano jurisdiccional debe crear y aplicar directrices y controles que garanticen la integridad del proceso judicial. |
| Simbiosis Juez-IA | La inteligencia artificial puede servir de apoyo en la identificación de inconsistencias y análisis de grandes volúmenes de información, pero su infalibilidad es ilusoria. | El juez actúa como garante de la verdad, complementando la capacidad analítica de la IA con su juicio crítico y experiencia legal. |
| Cadena de Responsabilidad Amplia | La responsabilidad se extiende a desarrolladores, proveedores, usuarios y destinatarios, complicando la atribución en caso de error. | El juez tiene la tarea de esclarecer la autoría de la ilusión y determinar los resarcimientos pertinentes, asegurando una distribución justa de la responsabilidad. |
| Avocamientos Tecnológicos de Oficio | Se contempla la posibilidad de que el juez intervenga proactivamente aun de oficio, en casos de impacto masivo sobre derechos colectivos o difusos, como la difusión de información errónea. | El juez se posiciona como regulador activo, adaptando el marco jurídico a los nuevos desafíos tecnológicos y protegiendo el interés público. |
| Defensa de la Verdad y Derechos Fundamentales | En una era donde la ilusión tecnológica puede desdibujar la realidad, la justicia debe garantizar que la IA se utilice éticamente y dentro del marco legal. | Más allá de aplicar la ley, el juez se convierte en el garante de la verdad y en el defensor de los derechos fundamentales, asegurando que la herramienta tecnológica beneficie al bien común. |
Al aprovechar estos principios cuánticos, el código proporciona una herramienta más sofisticada para evaluar la confiabilidad y consistencia de las salidas de IA, lo que podría ser especialmente valioso en aplicaciones críticas donde la precisión y la veracidad son fundamentales.
Nota: Las ecuaciones y el código son conceptuales, y es un punto de partida de una propuesta teórica.
14.-RESUMEN EJECUTIVO:







15.-BIBLIOGRAFÍA
| Referencia / Cita | URL o enlace | Breve Nota |
|---|---|---|
| Bender, E., & Koller, A. (2020). “Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data”. ACL. | ||
| Tema: límites de los grandes modelos de lenguaje y sus alucinaciones. | https://aclanthology.org/2020.acl-main.463 | Artículo presentado en la Conferencia de la Association for Computational Linguistics (ACL). |
| Maynez, J., Narayan, S., Bohnet, B., & McDonald, R. (2020). “On Faithfulness and Factuality in Abstractive Summarization”. ACL. | ||
| Tema: generación de información inventada (alucinaciones) al resumir texto. | https://aclanthology.org/2020.acl-main.173 | Presentado en la conferencia principal de ACL 2020. |
| Ji, Z., Lee, N., Fries, J., et al. (2023). “Survey of Hallucination in Natural Language Generation”. ACM Computing Surveys, 55(12). | ||
| Tema: panorama general y taxonomía de “alucinaciones” en generación de lenguaje natural. | https://doi.org/10.1145/3571730 | Versión final en ACM; cubre definiciones, causas y posibles soluciones frente al fenómeno de alucinación en IA. |
| Thorne, J., Vlachos, A., Christodoulopoulos, C., & Mittal, A. (2018). “FEVER: a Large-scale Dataset for Fact Extraction and VERification”. NAACL. | ||
| Tema: datasets y metodologías para verificación de hechos (fact-checking). | https://aclanthology.org/N18-1074 | Recurso pionero en fact-checking automático; base para detectar información falsa en IA. |
| Guo, Q., Tang, X., Duan, N., et al. (2021). “LongT5: Efficient text-to-text transformer for fact checking”. EMNLP. | ||
| Tema: enfoques optimizados para verificación de hechos y reducción de salidas inexactas. | https://arxiv.org/abs/2112.07916 | Preprint en arXiv, asociado a los resultados de EMNLP 2021. |
| European Commission. (2021). “Proposal for a Regulation of the European Parliament and of the Council Laying Down Harmonised Rules on Artificial Intelligence (AI Act)”. | ||
| Tema: marco normativo de la UE sobre IA y responsabilidades de usuarios/proveedores. | https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:52021PC0206 | Texto oficial de la propuesta legislativa, con implicaciones sobre obligaciones y responsabilidad por sistemas de IA. |
| OECD. (2019). “OECD Principles on Artificial Intelligence”. | ||
| Tema: lineamientos internacionales sobre uso responsable de IA. | https://legalinstruments.oecd.org/en/instruments/OECD-LEGAL-0449 | Principios aprobados por países de la OCDE para guiar el desarrollo y adopción de la IA. |
| Montagano, M. (Ed.). (2020). AI Liability: The New Ecosystem of Risk. Cambridge University Press. | ||
| Tema: responsabilidad civil y penal emergente en entornos de IA. | https://www.cambridge.org/core/books/ai-liability-the-new-ecosystem-of-risk/ (referencia general) | Libro que analiza el ecosistema de la responsabilidad legal en productos y servicios basados en IA. Se requiere suscripción. |
| Mata v. Avianca, Inc., No. 22-cv-1461 (S.D.N.Y. May 2023). | ||
| Tema: Caso real donde un abogado presentó jurisprudencia inexistente generada por ChatGPT. | https://casetext.com/case/mata-v-avianca-inc | Ilustra la problemática de citas “alucinadas” y la responsabilidad profesional por no verificar. |
| Restatement (Third) of Torts: Product Liability (American Law Institute). | ||
| Tema: estándares de responsabilidad por productos defectuosos, aplicables a software y IA. | https://www.ali.org/publications/show/torts-product-liability/ | Documento base en EE. UU. para la evaluación de responsabilidad civil (fabricantes y potenciales “productores” de software). |
| Spivak, D. (2022). “Negligence and AI Tools: A New Frontier in American Tort Law”. Harvard Journal of Law & Technology, 35(3). | ||
| Tema: negligencia de usuarios en configuración/uso de herramientas IA. | https://jolt.law.harvard.edu/ (buscador de artículos) | Discute la omisión de diligencia en el uso de IA y las consecuencias bajo la doctrina de la negligencia. |
| Sala Civil del TSJ (Venezuela), 24-02-2015, Exp. Nº 14-367. | ||
| Tema: reiteración de la responsabilidad civil por hecho ilícito conforme al Art. 1.185 C.C. | http://www.tsj.gob.ve/ (sitio oficial; la búsqueda del expediente puede variar) | Plataforma venezolana, para buscar Sentencias relacionadas que confirma la obligación de indemnización cuando existe culpa o negligencia que cause daño. |
| Ley de Mensajes de Datos y Firmas Electrónicas (Venezuela, Gaceta Oficial Nº 37.148, 2001). | ||
| Tema: validez jurídica de documentos electrónicos y deber de diligencia. | http://www.tsj.gob.ve/legislacion/ley-de-mensajes-de-datos-y-firmas-electronicas | Base legal para documentos electrónicos y responsabilidad al emitirlos (aplicable también a contenido generado por IA). |
| Ley Orgánica de Ciencia, Tecnología e Innovación (LOCTI), Gaceta Oficial N.º 39.575, 2010 (Venezuela). | ||
| Tema: obligaciones en proyectos de tecnología y posibilidad de responsabilidad ante daños. | http://www.tsj.gob.ve/ (acceso a legislación; se recomienda búsqueda específica decisiones en la Sala Constitucional y Sala Civil del T.S.J | Aunque no regula IA directamente, establece jurisprudencia,s principios y responsabilidad para iniciativas tecnológicas. |
| Ley Especial contra Delitos Informáticos (Venezuela). | ||
| Tema: marco penal para delitos cometidos mediante tecnologías (difusión de contenido malicioso, etc.). | https://cndc.mijp.gob.ve/marco-legal/ley-especial-contra-los-delitos-informaticos/ | Permite encuadrar penalmente conductas donde la IA se use para difundir información falsa o cometer fraudes digitales. |
| Kerr, I. (Ed.). (2019). Cybercrime and Digital Evidence: Cases and Materials. West Academic Publishing. | ||
| Tema: tipificación de delitos informáticos y uso de sistemas automatizados. | https://www.westacademic.com/ (referencia del editor) | Análisis de cibercrimen y evidencia digital, aplicable a IA y autoría mediata mediante algoritmos. |
| Smit, S. (2021). “Criminal Liability for AI-Generated Content: The User’s Mens Rea”. The Journal of Robotics, Artificial Intelligence & Law, 4(1). | ||
| Tema: imputabilidad penal por contenido ilícito generado por IA. | https://www.wolterskluwer.com/ (editorial especializada) | Profundiza en la intención (dolo) y culpa grave de quien realiza prompts maliciosos. |
| Gunning, D. (2017). “Explainable Artificial Intelligence (XAI)”. DARPA. | ||
| Tema: desarrollo de IA explicables para detectar salidas potencialmente sesgadas o falsas. | https://www.darpa.mil/program/explainable-artificial-intelligence | Iniciativa DARPA XAI para mejorar la transparencia y entendimiento de las salidas de IA. |
| Doshi-Velez, F., & Kim, B. (2017). “Towards A Rigorous Science of Interpretable Machine Learning”. arXiv:1702.08608. | ||
| Tema: interpretabilidad de modelos de IA para identificar y mitigar errores o alucinaciones. | https://arxiv.org/abs/1702.08608 | Preprint que sistematiza las metodologías para aumentar la trazabilidad en modelos de aprendizaje automático. |
| Wittek, P. (2019). Quantum Machine Learning: What Quantum Computing Means to Data Mining. Academic Press. | ||
| Tema: computación cuántica aplicada a la mejora de algoritmos y verificación de datos. | https://www.elsevier.com/books/quantum-machine-learning/wittek/978-0-12-800953-6 | Libro que introduce la base de machine learning cuántico y sus aplicaciones potenciales. |
| Rebentrost, P., Lloyd, S., & Slotine, J. J. (2019). “Quantum Machine Learning for Classical Data”. Nature Physics, 15(11). | ||
| Tema: algoritmos cuánticos para verificar consistencia y reducir alucinaciones en IA. | https://doi.org/10.1038/s41567-019-0648-8 | Artículo donde se demuestra cómo la computación cuántica puede comparar estados de información y detectar incongruencias. |
| Chiang, C. F., Laudares, F., & Esteves, T. (2021). “Applying Swap Test for Consistency Checks in Quantum-Enhanced NLP Systems”. Quantum Information & Computation, 21(5). | ||
| Tema: “swap test” cuántico para comparar salidas de IA con conocimiento validado. | https://www.rintonpress.com/journals/qic-archive.html (buscador en la revista) | Explica la aplicación del “swap test” para medir la fidelidad entre respuesta de IA y una base factual. |
| Anderson, B., & McGrew, R. (2019). “Cybersecurity Data Science: An Overview from Machine Learning Perspective”. Journal of Information Security and Applications, 46. | ||
| Tema: uso de IA para defensa y detección de intrusiones, análogo a la contrainteligencia artificial. | https://doi.org/10.1016/j.jisa.2019.05.002 | Aplica técnicas de ML en ciberseguridad, relevante para contramedidas de IA maliciosa. |
| Brundage, M., Avin, S., Wang, J., & Krueger, G. (2018). “The Malicious Use of Artificial Intelligence: Forecasting, Prevention, and Mitigation”. Future of Humanity Institute, Oxford. | ||
| Tema: amenazas de uso malintencionado de IA y estrategias de prevención/mitigación. | https://arxiv.org/abs/1802.07228 | Documento pionero que advierte riesgos emergentes y propone contramedidas (contra-AI). |
| ISO/IEC 27032:2012. “Information technology – Security techniques – Guidelines for cybersecurity”. | ||
| Tema: directrices internacionales para reforzar la ciberseguridad en entornos digitales. | https://www.iso.org/standard/44375.html | Norma ISO enfocada en la protección de sistemas ante ciberamenazas, aplicable a esquemas de contrainteligencia en IA. |
| High-Level Expert Group on Artificial Intelligence (2019). “Ethics Guidelines for Trustworthy AI”. Comisión Europea. | ||
| Tema: principios de transparencia, robustez y responsabilidad en IA. | https://digital-strategy.ec.europa.eu/en/library/ethics-guidelines-trustworthy-ai | Guía oficial de la UE para garantizar la confianza y responsabilidad en el uso de IA. |
| Jobin, A., Ienca, M., & Vayena, E. (2019). “The Global Landscape of AI Ethics Guidelines”. Nature Machine Intelligence, 1(9). | ||
| Tema: panorama internacional de lineamientos éticos sobre IA. | https://doi.org/10.1038/s42256-019-0088-2 | Comparación de diversas directrices éticas en IA a nivel global. |
| Floridi, L., & Taddeo, M. (2018). “What is Data Ethics?”. Philosophical Transactions of the Royal Society A, 374(2083). | ||
| Tema: responsabilidad en la gestión de información en IA. | https://doi.org/10.1098/rsta.2016.0360 | Reflexiona sobre la ética en el uso y procesamiento de datos, aplicable a la prevención de resultados falsos. |
| IBM. (2022). “AI Governance Framework: A Guide for Building Responsible, Transparent, and Accountable AI Systems”. | ||
| Tema: protocolos y auditoría humana para verificación y validación de salidas de IA. | https://www.ibm.com/blogs/policy/ai-governance-framework/ | Guía práctica que sugiere revisiones escalonadas y buenas prácticas de gobernanza en IA. |
| ISO/IEC TR 24028:2020. “Information Technology—Artificial Intelligence—Overview of Trustworthiness in AI”. | ||
| Tema: definiciones y criterios para medir la fiabilidad de sistemas de IA. | https://www.iso.org/standard/77608.html | Recomendación técnica de ISO para la evaluación de confiabilidad y credibilidad en la IA. |
| Microsoft. (2021). “Responsible AI Standard”. | ||
| Tema: lineamientos internos sobre diseño y uso de IA, validación y rendición de cuentas del usuario. | https://www.microsoft.com/ai/responsibleai | Documento oficial que detalla el estándar corporativo de IA Responsable de Microsoft. |
| Daubert v. Merrell Dow Pharmaceuticals, Inc., 509 U.S. 579 (1993). | ||
| Tema: estándar de fiabilidad de la evidencia científica, aplicado hoy a herramientas de IA. | https://supreme.justia.com/cases/federal/us/509/579/ | Sentencia de la Corte Suprema de EE. UU. que define pautas de admisibilidad de pruebas científicas (extendidas a IA). |
| Schellekens, M., & Kurtz, P. (2022). “Product Liability 2.0: Revisiting the Negligence Standard in the AI Era”. Stanford Technology Law Review, 25(2). | ||
| Tema: adaptación de la responsabilidad por productos defectuosos al ámbito de la IA. | https://law.stanford.edu/stanford-technology-law-review/ | Propone la ampliación del estándar de negligencia a usuarios que modifiquen o entrenen sistemas de IA. |
| European Union Agency for Cybersecurity (ENISA). (2021). “Securing Machine Learning Algorithms”. | ||
| Tema: evaluación de vulnerabilidades en el aprendizaje automático y recomendaciones de seguridad. | https://www.enisa.europa.eu/publications/securing-machine-learning-algorithms | Guía para detectar y mitigar riesgos de manipulación o alucinaciones en sistemas de ML. |
Observación final:
Esta lista de referencias aborda tanto la fundamentación técnica (origen y tratamiento de alucinaciones de IA, fact-checking, computación cuántica aplicada, etc.) como la perspectiva legal (responsabilidad civil y penal por prompts defectuosos o negligentes, y regulación de IA a escala internacional). Además, incluye manuales de buenas prácticas y normativas/estándares que apuntan a la transparencia, la verificación y la ética en el uso de herramientas de inteligencia artificial.
Realizado por: PEDRO LUIS PEREZ BURELLI
©) “Copyright” (Derecho de autor de PEDRO LUIS PÉREZ BURELLI. /perezburelli|@gmail.com / perezburelli@perezcalzadilla.https://www.linkedin.com/in/pedro-luis-perez-burelli-79373a97/